实验评估(Evaluation)
实验评估(Evaluation)
LLM 评估
下列示例展示了如何对于 opai.chat.completions 风格的 LLM 进行记录和评估,并通过可视化形式对比不同 LLM 的执行结果。
import os
os.environ["OPENAI_API_BASE"] = "<你的 OPENAI API BASE URL>"
os.environ["OPENAI_API_KEY"] = "<你的 OPENAI API KEY>"
model_name = "<模型名称>"
import pandas as pd
import mlflow
import openai
# 创建实验
mlflow.set_experiment("LLM Evaluation")
mlflow.start_run()
# 记录系统提示词作为运行参数
system_prompt = (
"你是一个诗人,你可以创作出能唤起人们情感并有力量搅动人们灵魂的诗篇。"
"无论写任何话题或主题,需要确保你的文字以美丽而有意义的方式传达你所要表达的感觉。"
"你也可以想出一些短小的诗句,但仍有足够的力量在读者心中留下印记。"
)
mlflow.log_param("系统提示词", system_prompt)
# 记录 opai.chat.completions 风格的模型
logged_model = mlflow.openai.log_model(
model=model_name,
task=openai.chat.completions,
artifact_path="model",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": "话题:{question}"},
],
)
# 评估模型
questions = pd.DataFrame(
{
"question": [
"大海",
"工作",
"飞机",
]
}
)
mlflow.evaluate(
model=logged_model.model_uri,
model_type="question-answering",
data=questions,
)
mlflow.end_run()
# 加载评估结果
results: pd.DataFrame = mlflow.load_table(
"eval_results_table.json", extra_columns=["run_id", "params.system_prompt"]
)
print("Evaluation results:")
print(results)查看评估记录
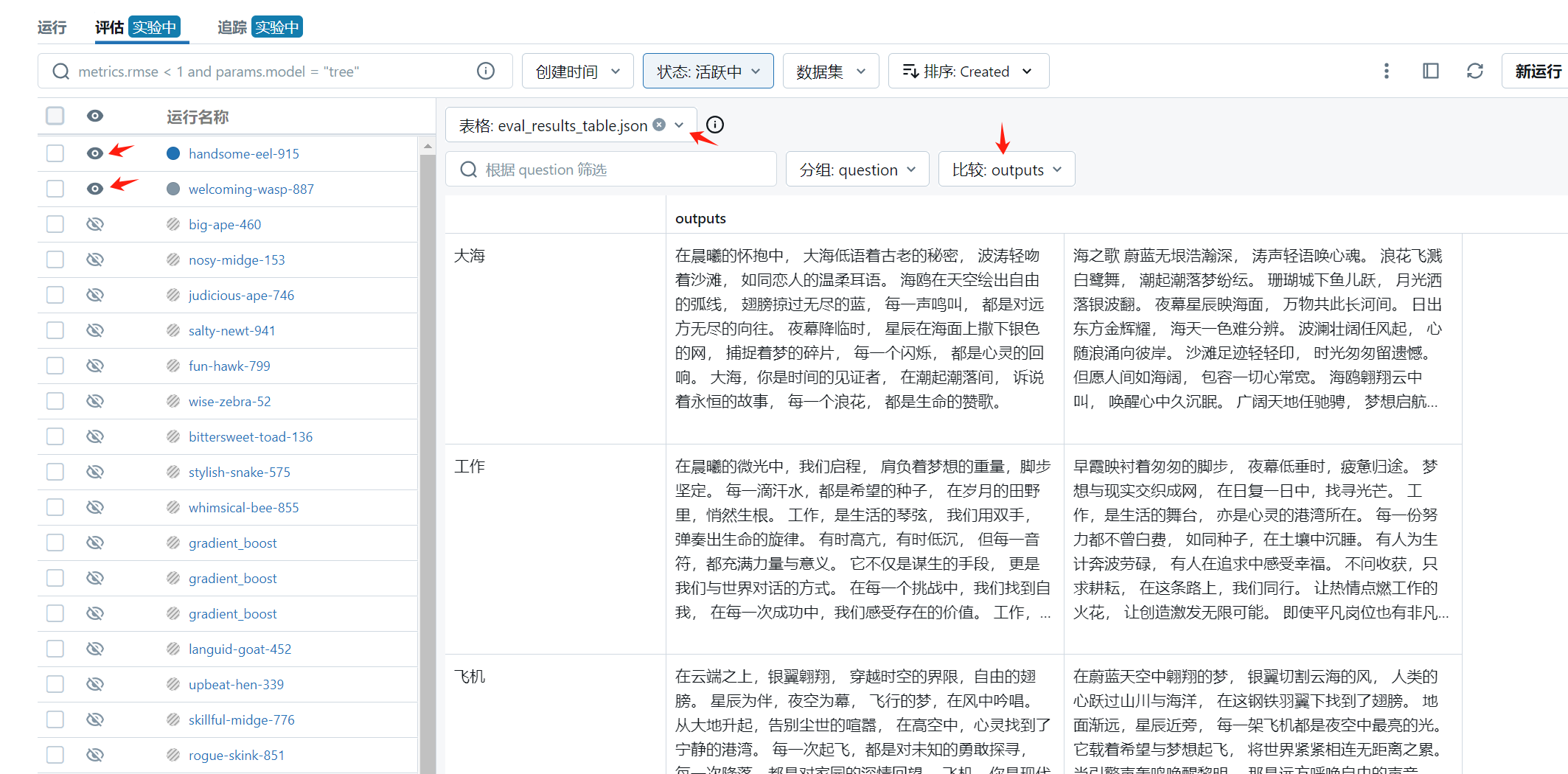
在 模型/实验 中找到 LLM Evaluation,点击 评估 查看记录。
- 左侧选择需要评估的运行记录,点击
隐藏或取消隐藏可以更改用于评估的运行集合; - 选择
运行集合共有的评估文件进行可视化对比; - 更改
分组和对比指标从不同维度评估模型效果。
下图展示了 qwen-plus 和 deepseek-chat 在上述示例提示词下的执行结果。