快速开始
快速开始
本文为您提供了如何使用 算场 Data+AI 平台 训练、注册、部署一个机器学习模型的全流程示例。
上传数据集
示例中使用了一个描述不同葡萄酒样本的数据集,该数据集来自 UCI 机器学习库,包括 winequality-white.csv 和 winequality-red.csv。
- 首先创建名称为
ml_quickstart的数据库,将数据集导入数据库中创建名称为winequality_white和winequality_red的数据表。
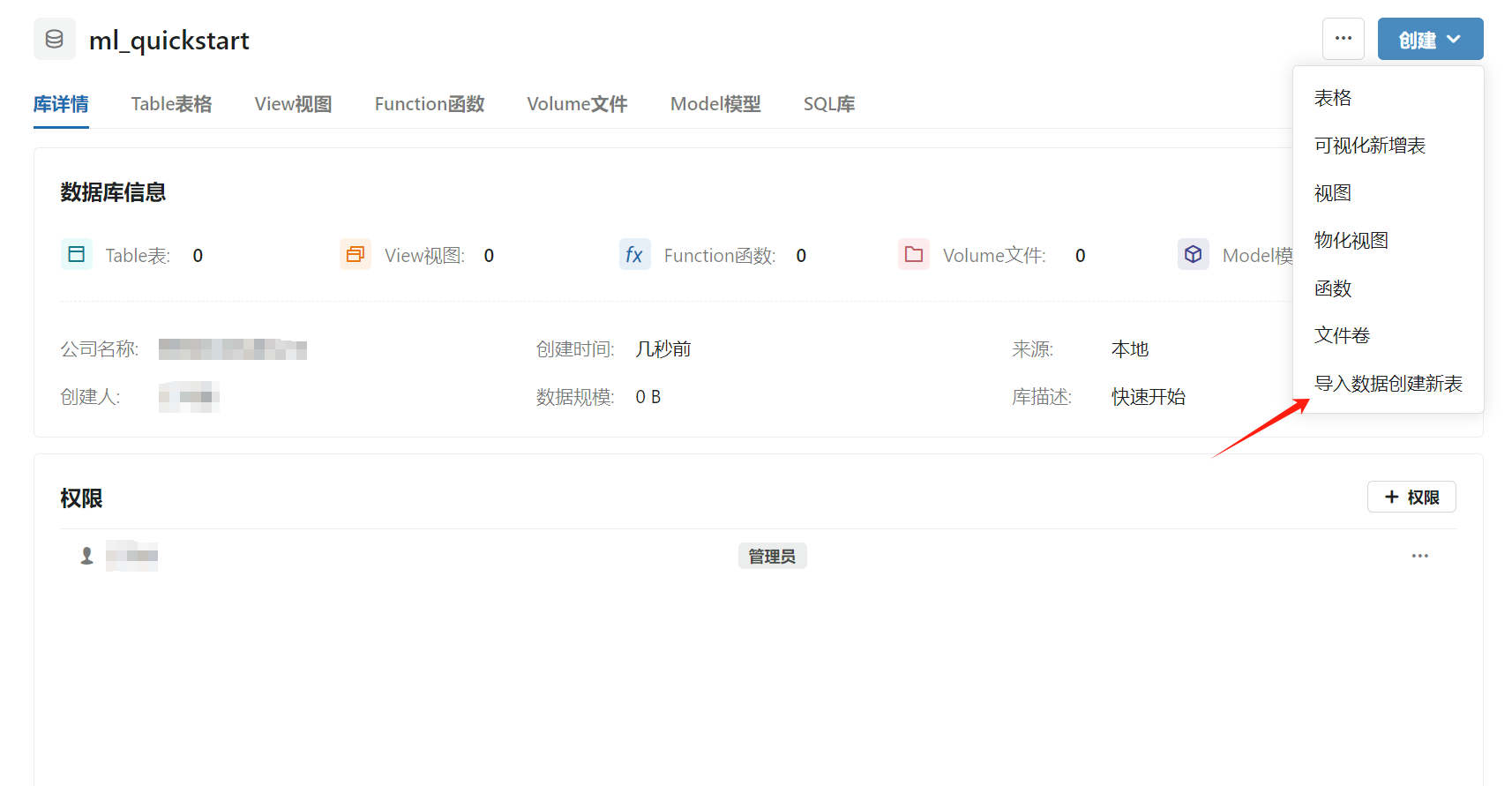
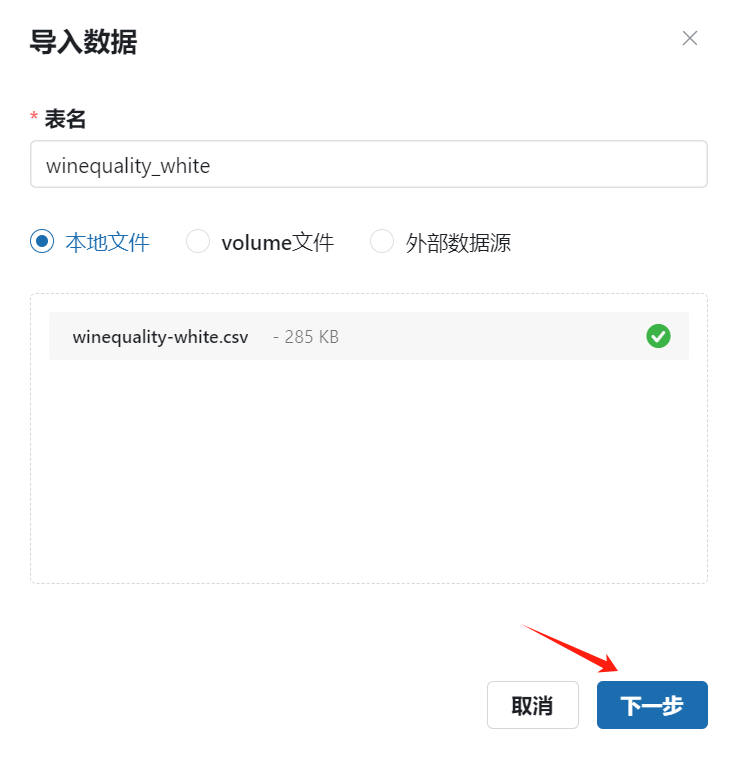
- 选择刚才下载的
winequality-white.csv文件
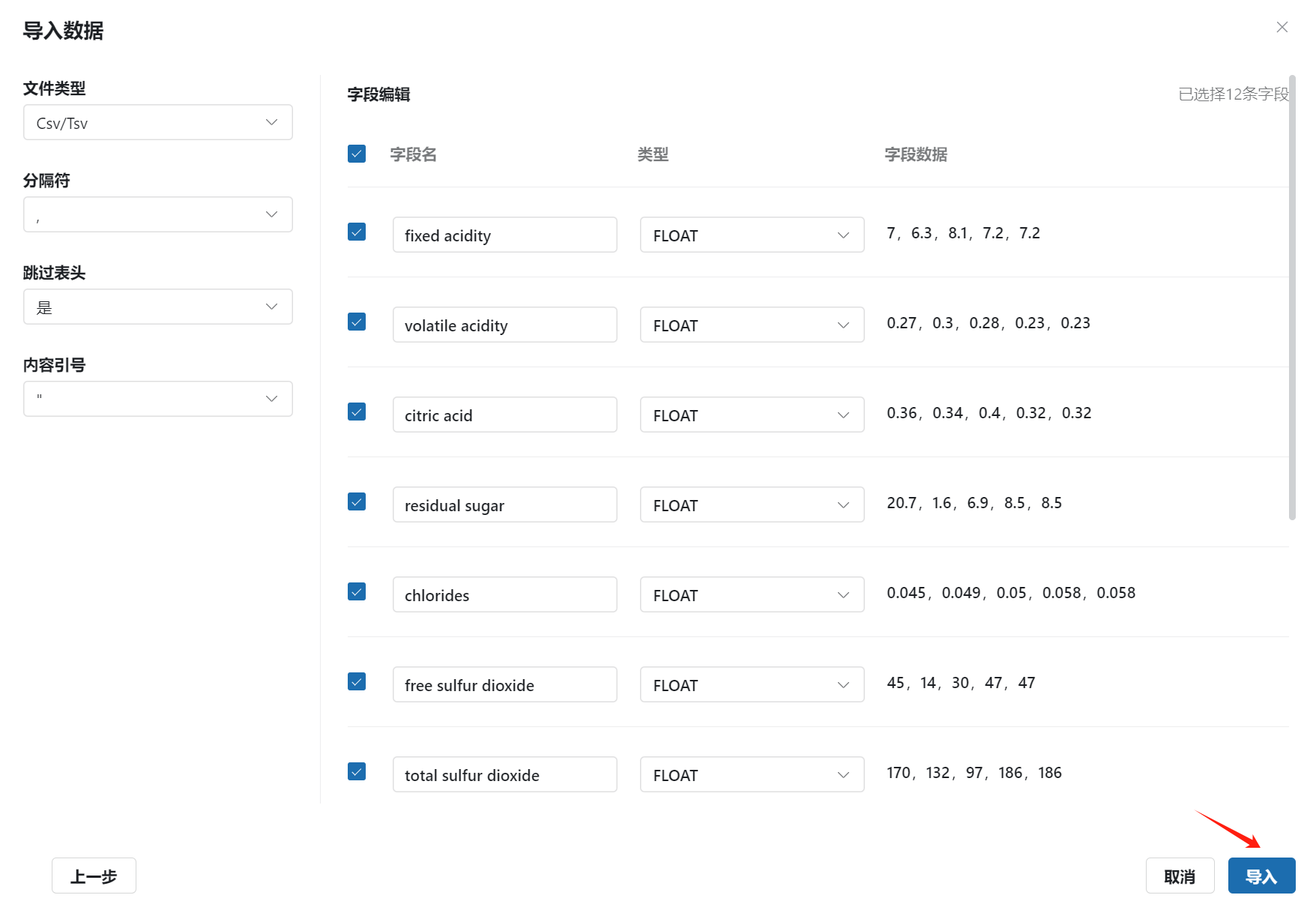
- 导入全部字段
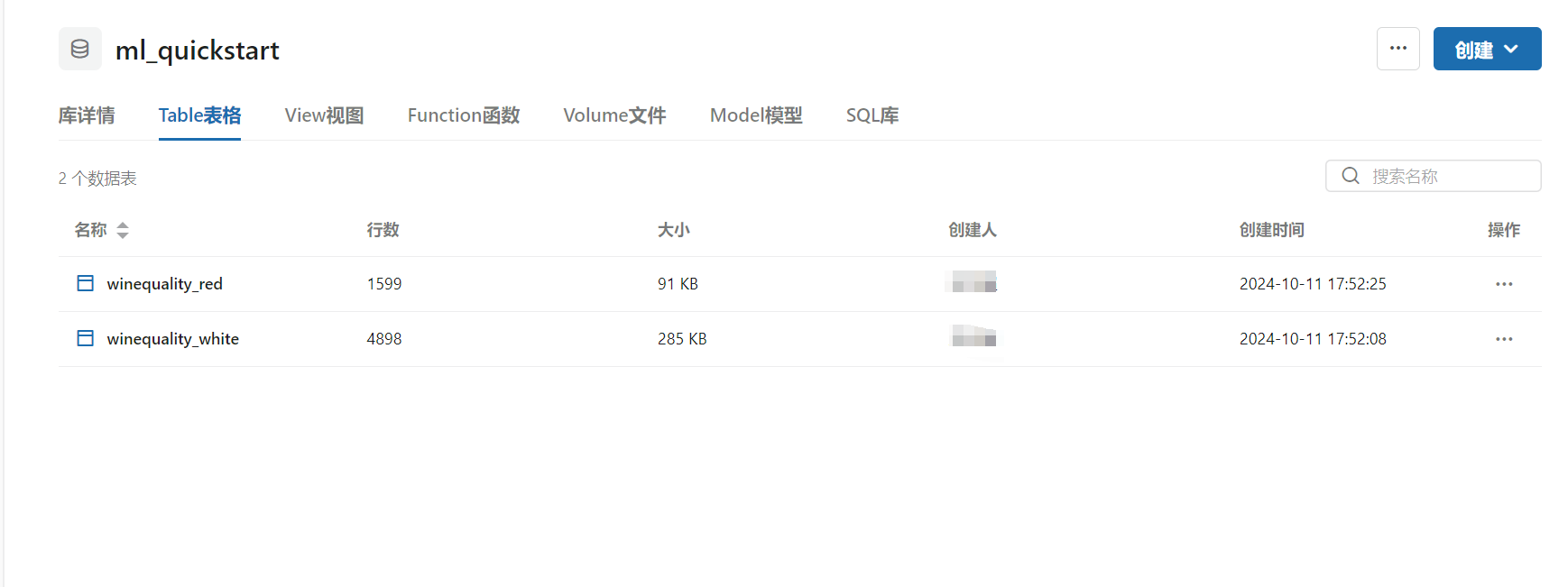
- 同样方式导入
winequality-red.csv创建winequality_red数据表
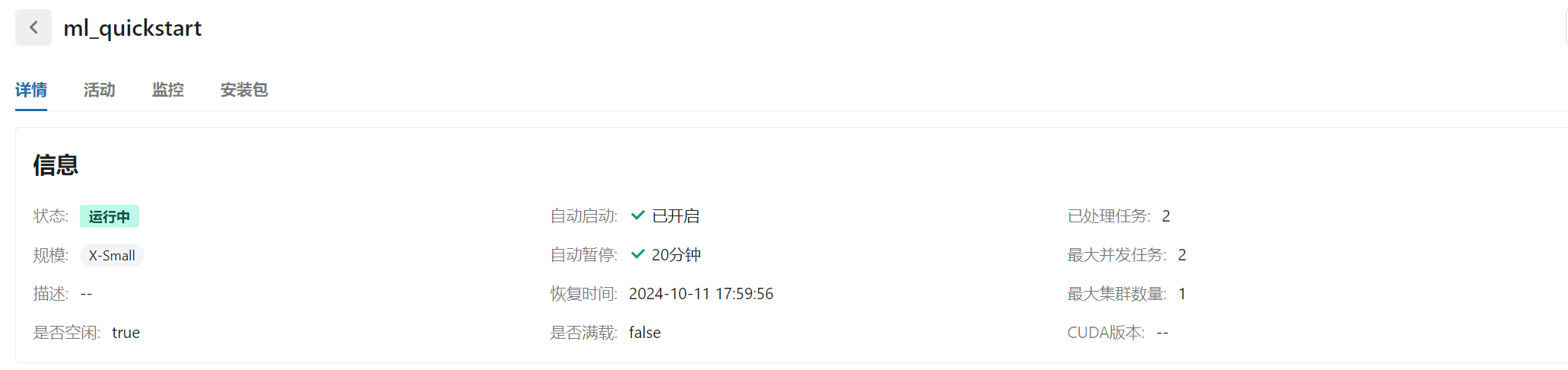
启动 CPU/GPU 集群
- 在算力模块创建
ML的CPU集群
- 新增集群
- 名称:
ml_quickstart - 集群类型:
ML - 集群规格:
X-Small
- 名称:

- 等待集群创建成功
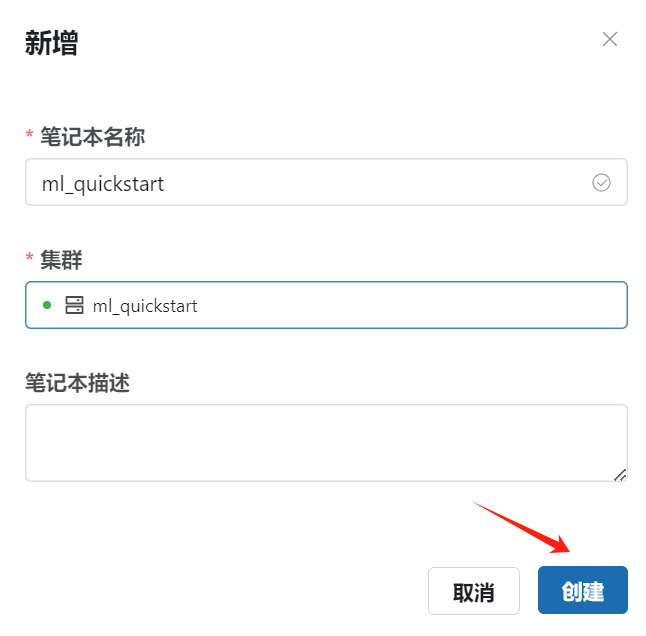
创建 Notebook
- 在
工作/笔记本中创建名称为ml_quickstart的 Notebook,选择刚才启动的ml_quickstart集群。
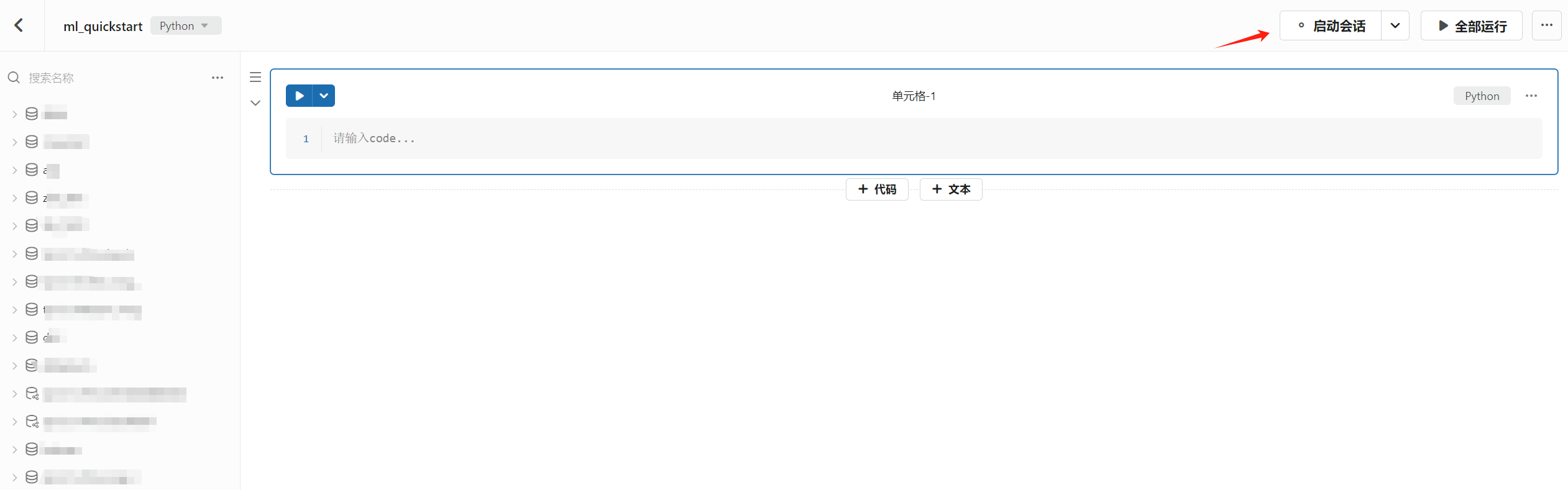
- 点击右上角的
启动会话为 Notebook 创建会话级别的运行环境
模型训练
库导入
您可以使用预安装的库, scikit-learn来训练模型,使用 MLflow 跟踪训练好的模型。
import mlflow
import numpy as np
import pandas as pd
import sklearn.datasets
import sklearn.metrics
import sklearn.model_selection
import sklearn.ensemble无输出加载数据集
spark.sql("use database ml_quickstart;")
white_wine = spark.read.table(f"winequality_white").toPandas()
red_wine = spark.read.table(f"winequality_red").toPandas()无输出处理并划分训练和测试集
# 预处理数据
white_wine['is_red'] = 0.0
red_wine['is_red'] = 1.0
data_df = pd.concat([white_wine, red_wine], axis=0)
# 基于葡萄酒质量定义分类标签
data_labels = data_df['quality'] >= 7
data_df = data_df.drop(['quality'], axis=1)
# 按照 8:2 比例划分训练集和测试集
X_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split(
data_df,
data_labels,
test_size=0.2,
random_state=1
)
X_train.shape, X_test.shape, y_train.shape, y_test.shape输出
((5197, 12), (1300, 12), (5197,), (1300,))开启 MLflow 自动记录
使用 mlflow.autolog() 自动记录训练过程中的数据、参数、指标和模型权重
注意,未指定实验名称时将会使用 默认实验(
Default)
# 开启 MLflow autologging
mlflow.autolog()输出
2024/10/11 18:28:14 INFO mlflow.tracking.fluent: Autologging successfully enabled for sklearn.模型训练
with mlflow.start_run(run_name='gradient_boost') as run:
model = sklearn.ensemble.GradientBoostingClassifier(random_state=0)
# 参数、训练指标和模型权重会被自动记录
model.fit(X_train, y_train)
predicted_probs = model.predict_proba(X_test)
roc_auc = sklearn.metrics.roc_auc_score(y_test, predicted_probs[:,1])
# 测试数据的AUC评分不会自动记录,需要手动记录
mlflow.log_metric("test_auc", roc_auc)
print("Test AUC of: {}".format(roc_auc))输出
Test AUC of: 0.8834365701533531实验管理
- 在
模型/实验的Default实验中查看创建的gradient_boost运行,在运行中记录了模型训练过程中使用的数据集、训练参数、指标和模型权重。
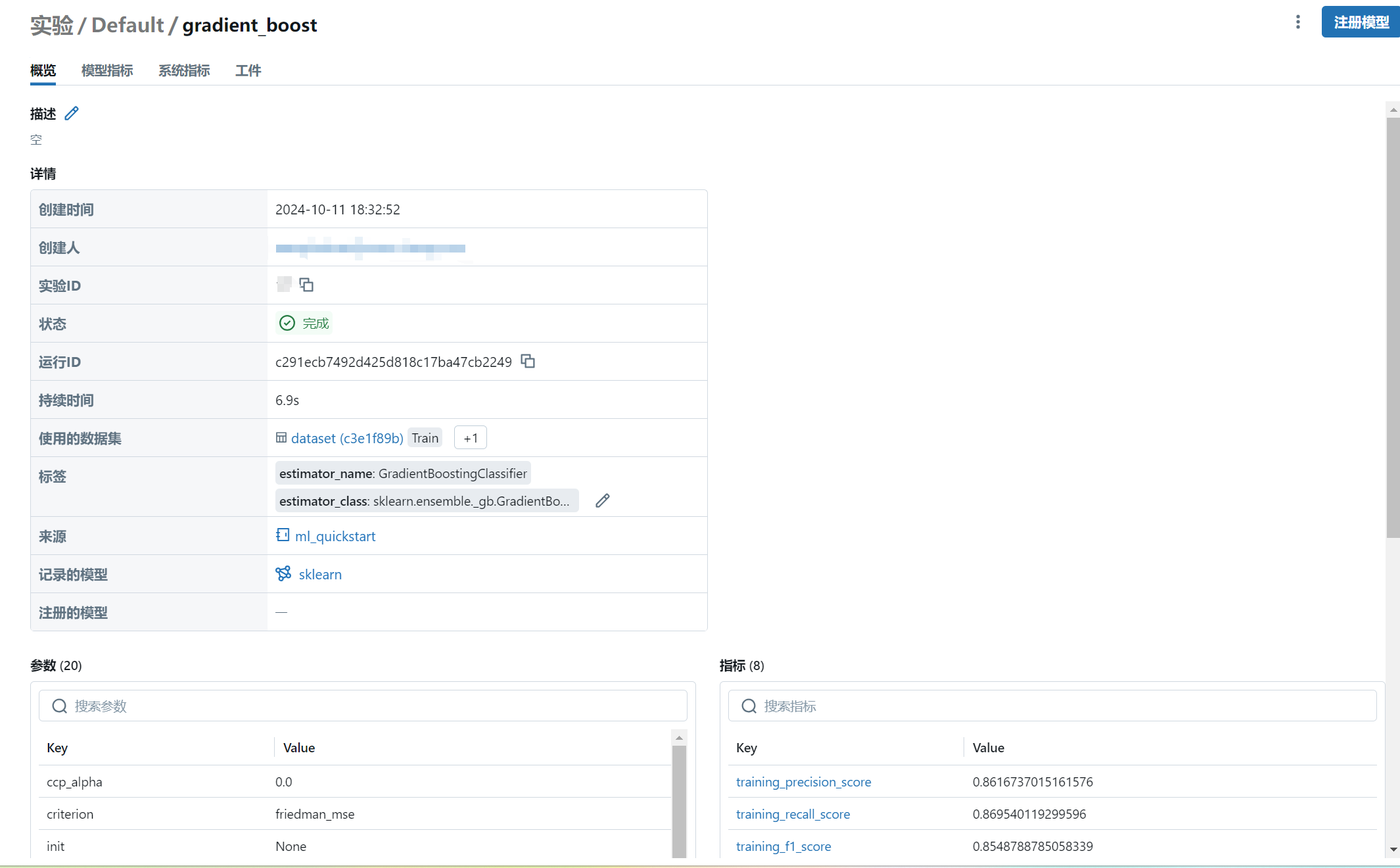
- 工件中记录了模型权重和运行环境
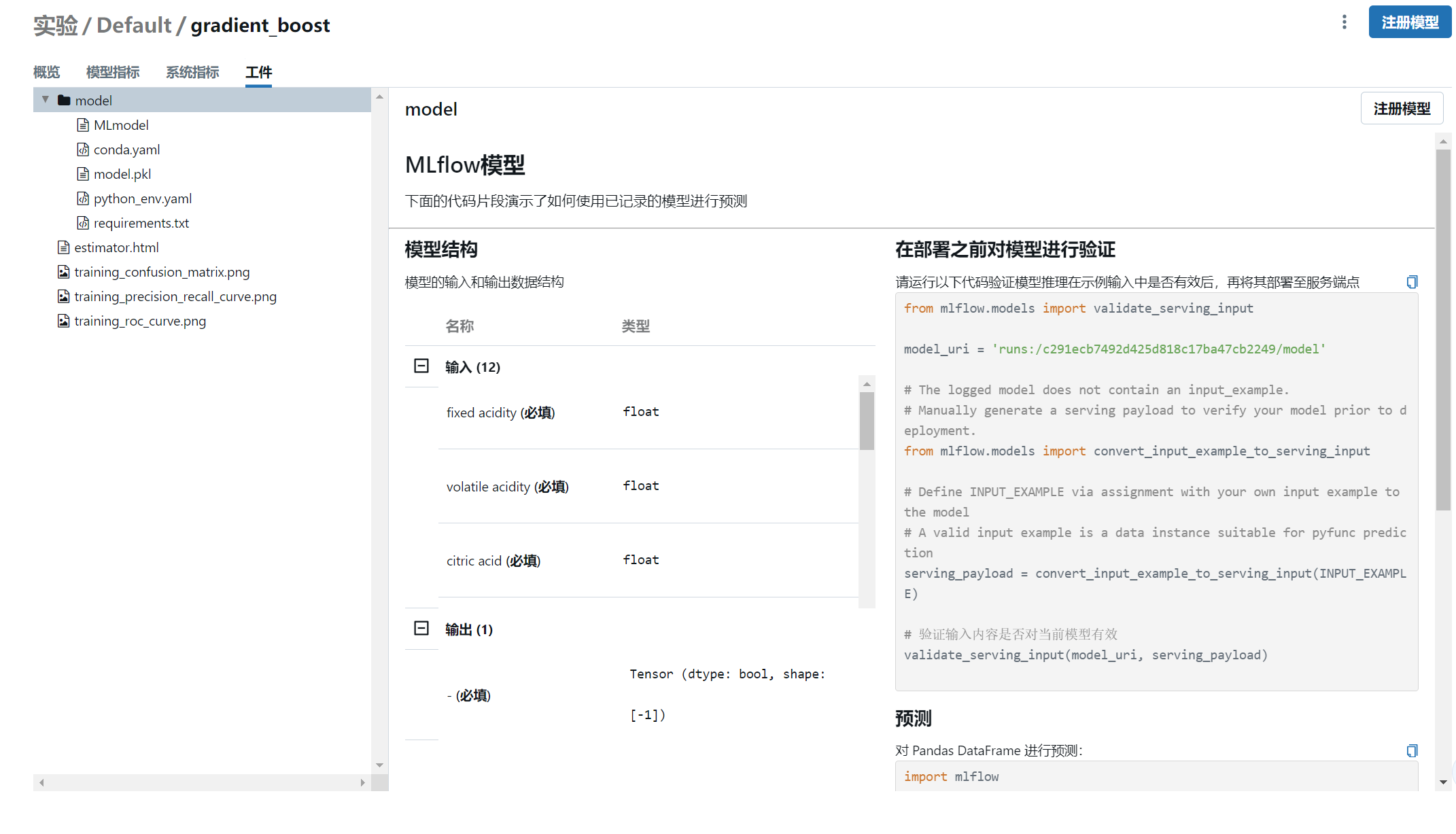
加载模型
对于记录后的模型可以根据需求加载使用
# 记录模型后,您可以将其加载到不同的笔记本或工作表中
model_loaded = mlflow.pyfunc.load_model(
'runs:/{run_id}/model'.format(
run_id=run.info.run_id
)
)
predictions_loaded = model_loaded.predict(X_test)
predictions_loaded输出
array([False, False, False, ..., False, True, False])模型注册
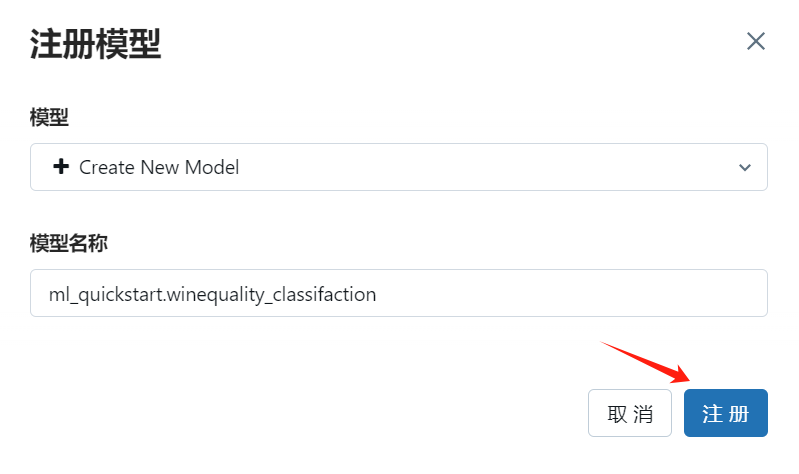
您可以在上述运行的界面中点击 注册模型 按钮将当前模型注册至 AI模型 中,也可以通过 API 注册指定模型。
UI
将运行中记录的模型权重注册为 ml_quickstart.winequality_classifaction,表示将当前模型命名为 winequality_classifaction,该模型位于数据库 ml_quickstart 下
注意:模型注册时为两级结构
db_name.model_name
API
注意:模型注册时为两级结构
db_name.model_name
model_name = "ml_quickstart.winequality_classifaction"
model_uri = "runs:/{}/model".format(run.info.run_id)
mlflow.register_model(model_uri, model_name)输出
Successfully registered model 'ml_quickstart.winequality_classifaction'.
2024/10/11 19:25:15 INFO mlflow.store.model_registry.abstract_store: Waiting up to 300 seconds for model version to finish creation. Model name: ml_quickstart.winequality_classifaction, version 1
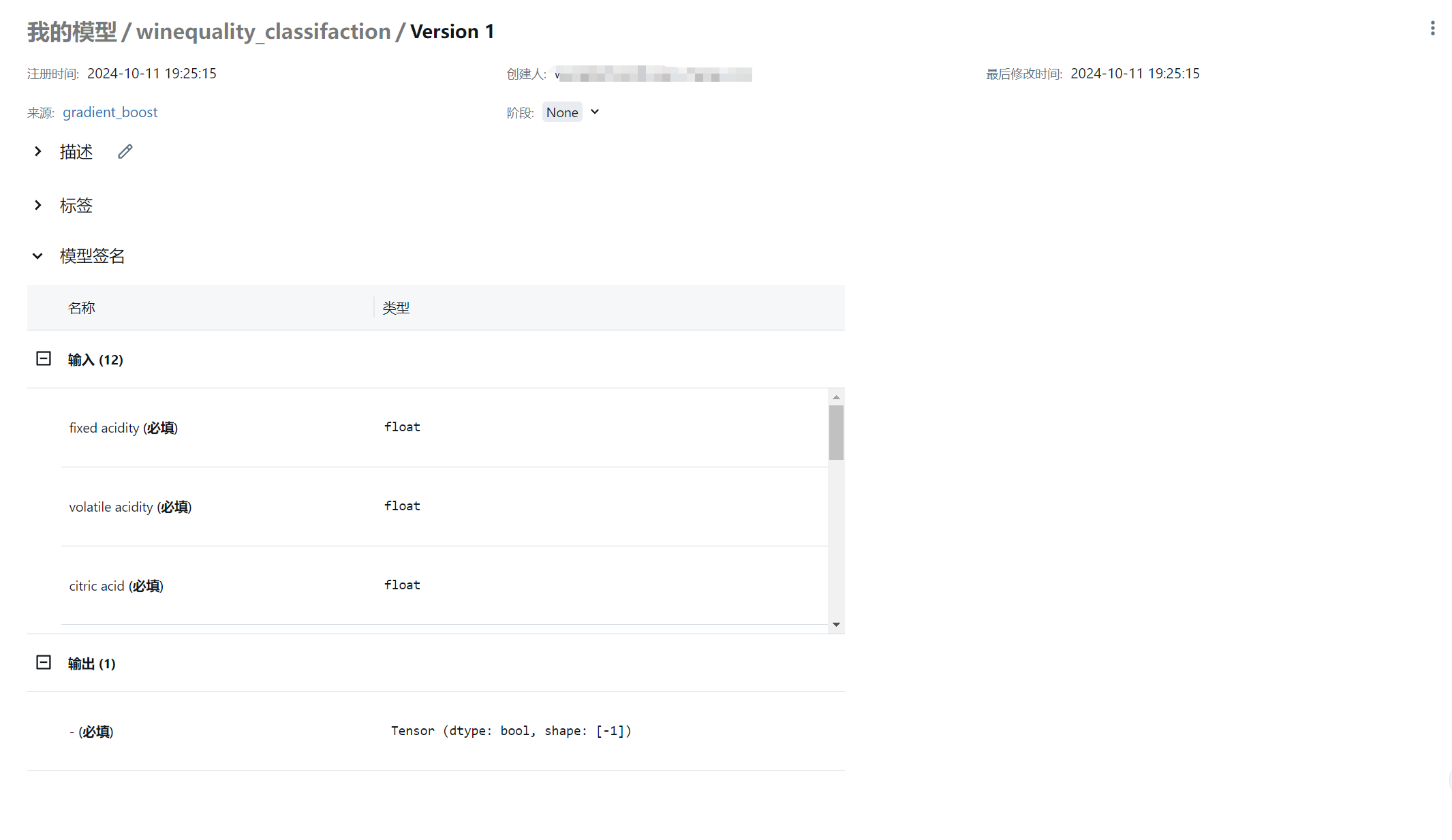
Created version '1' of model 'ml_quickstart.winequality_classifaction'.查看已注册模型
模型部署
创建在线服务
创建服务
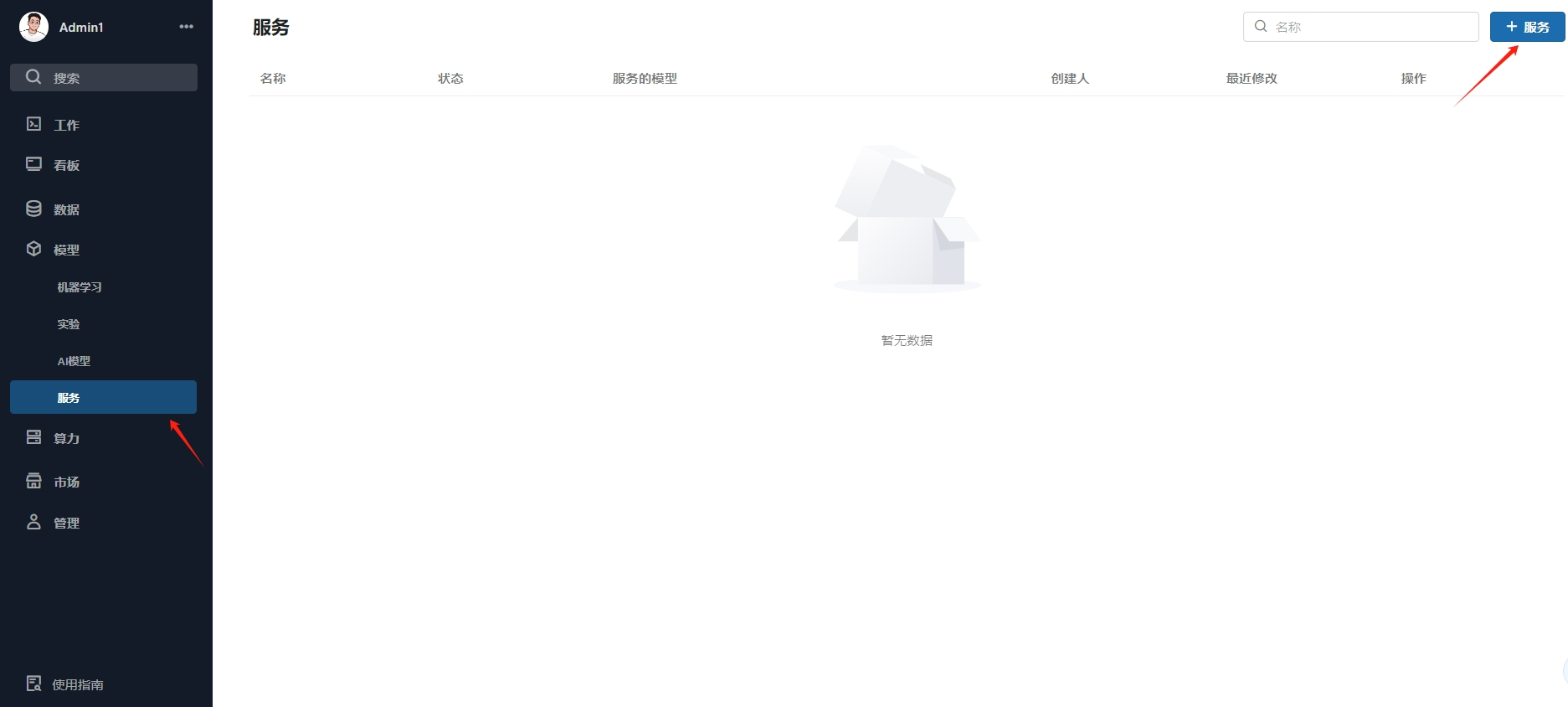
设置endpoint名称
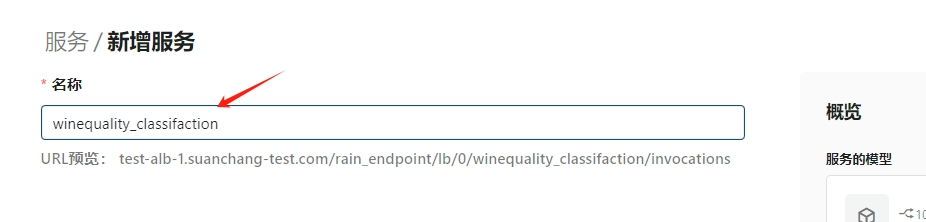
选择模型 版本
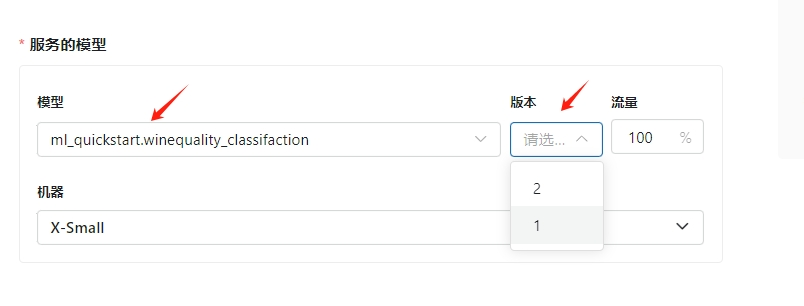
选择规格

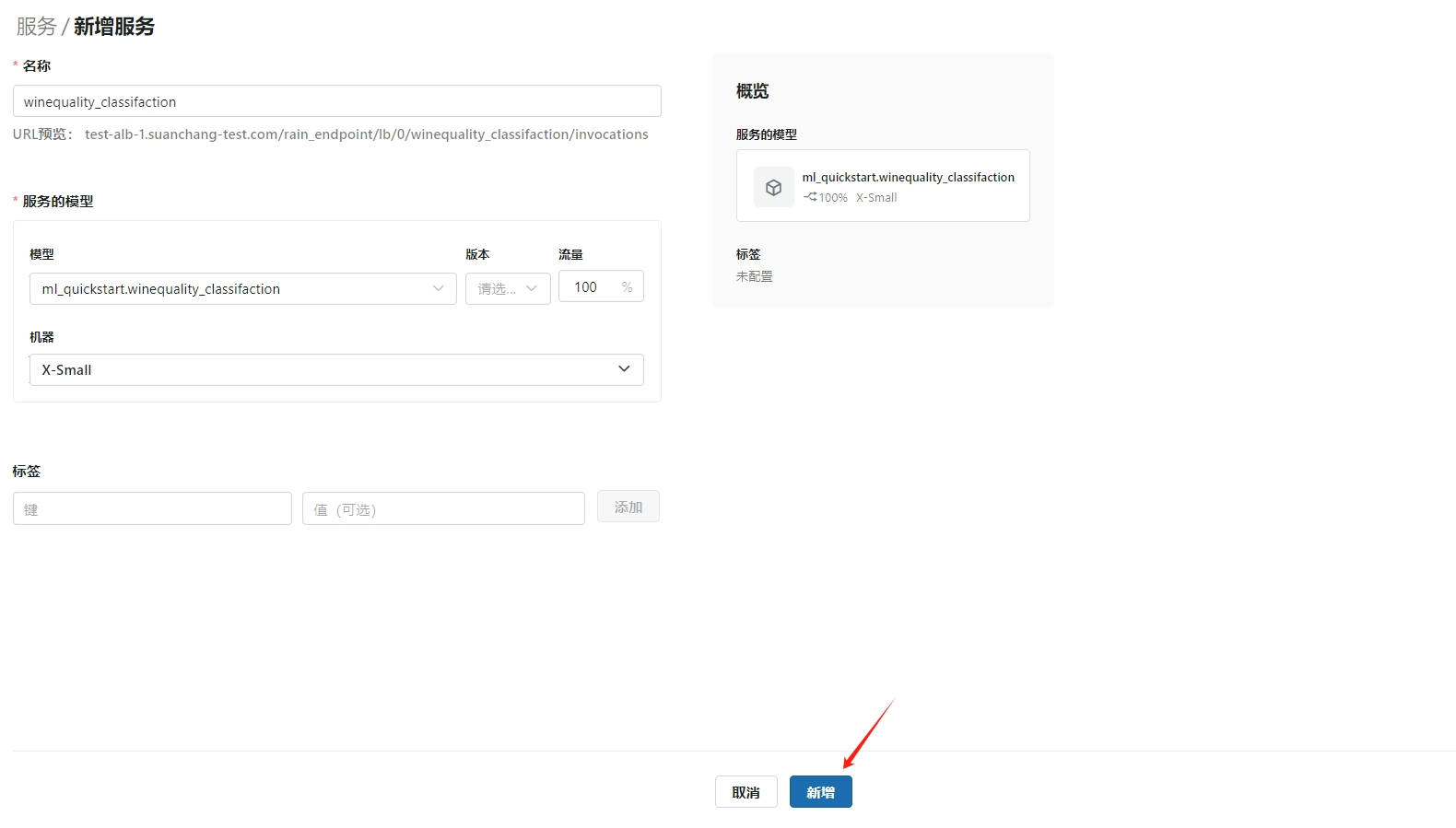
点击新增,创建 模型在线服务
初始服务状态为 打包中,针对不同模型类型、大小、依赖项等,打包状态将持续 5~30 分钟。
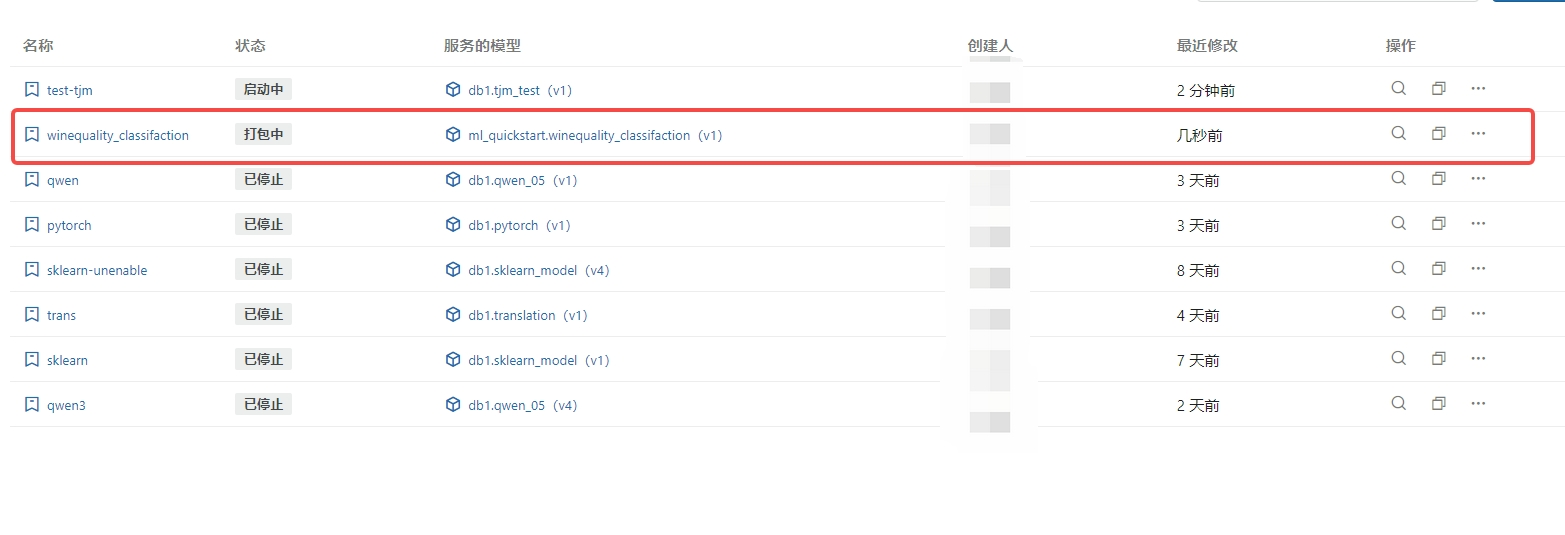
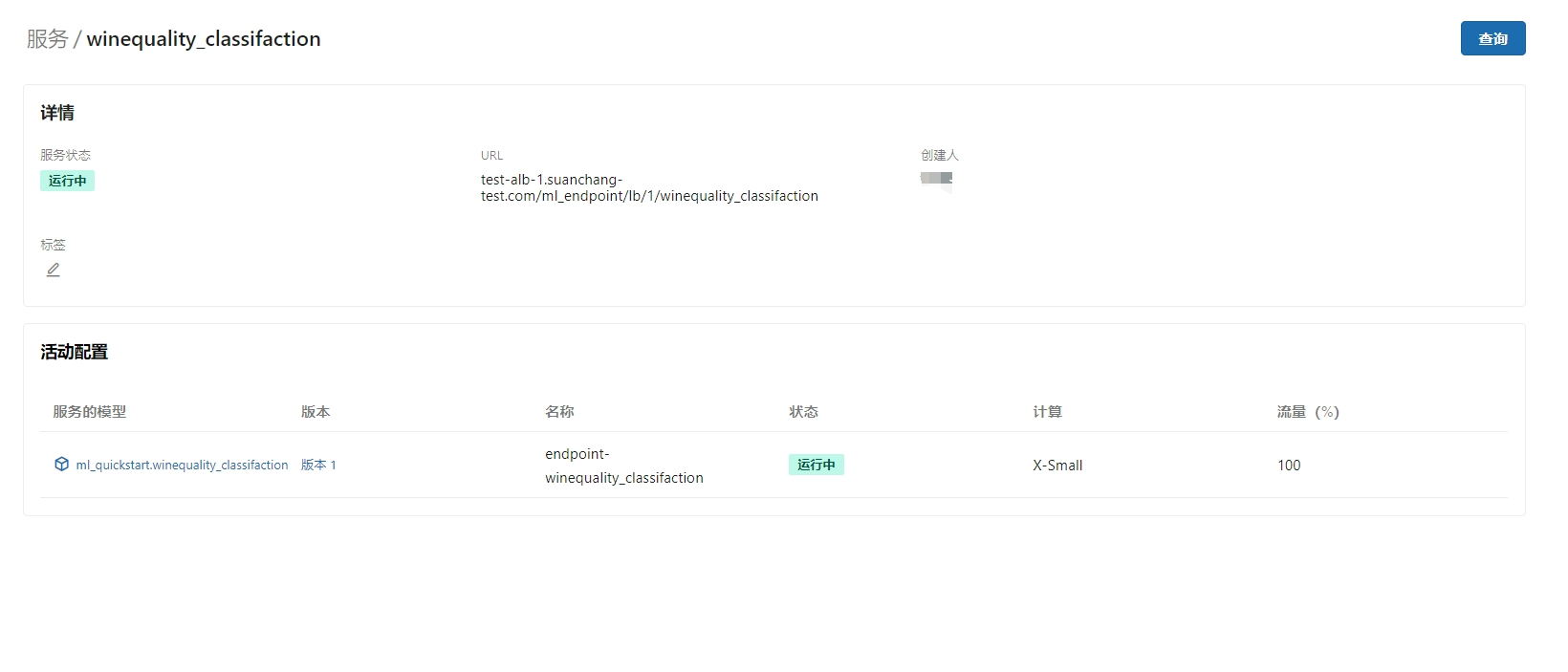
等待服务状态为 运行中 时, 模型在线服务 准备就绪,可以发起 API 调用。
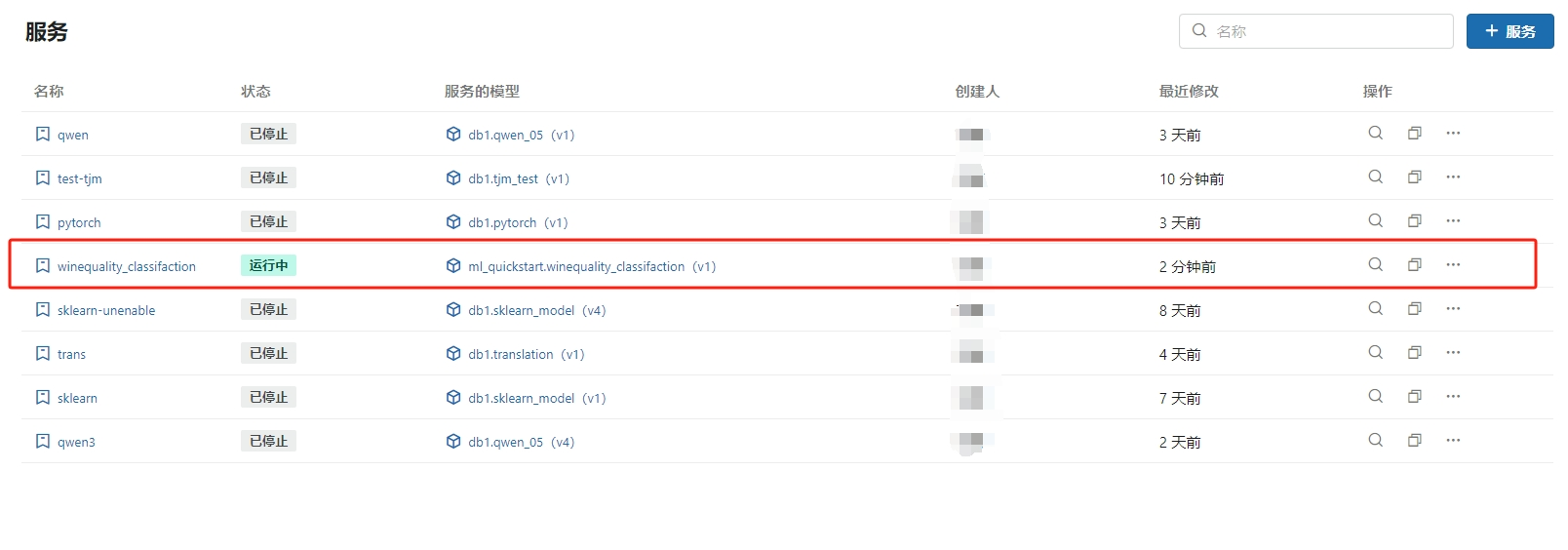
创建完成
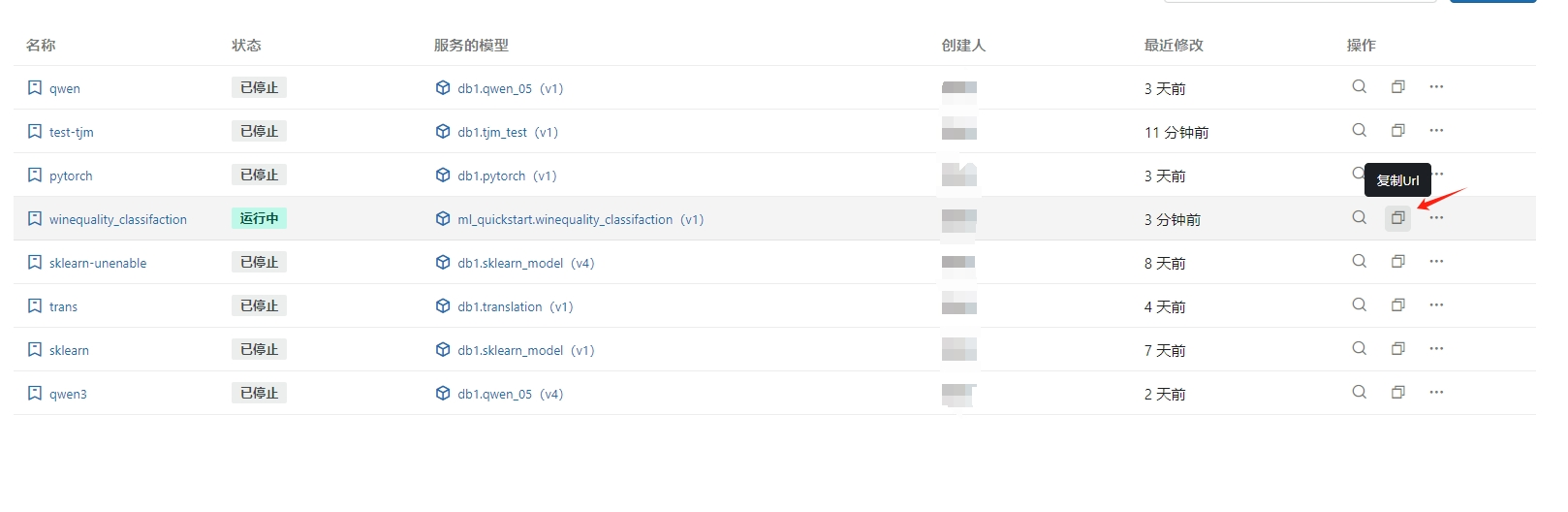
调用在线服务
对于服务状态为 运行中 的 模型在线服务 复制 url
发起 HTTP 调用
import requests
url = "http://test-alb-1.suanchang-test.com/ml_endpoint/lb/1/winequality_classifaction/invocations"
data = {
"inputs":{
"fixed acidity": 6.3,
"volatile acidity": 0.24,
"citric acid": 0.29,
"residual sugar": 13.7,
"chlorides": 0.035,
"free sulfur dioxide": 53.0,
"total sulfur dioxide": 134.0,
"density": 0.99567,
"pH": 3.17,
"sulphates": 0.38,
"alcohol": 10.6,
"is_red": 0.0
}
}
res = requests.post(url=url, json=data)
res.json()输出
{'predictions': [False]}