分类任务
分类任务
分类任务使用常见的机器学习算法,根据在训练数据中检测到的模式将数据分为不同的类别。支持二元分类(两个类别)和多类别分类(两个以上的类别)。分类的常见用例包括客户流失预测、信用卡欺诈检测和垃圾邮件检测。
数据准备
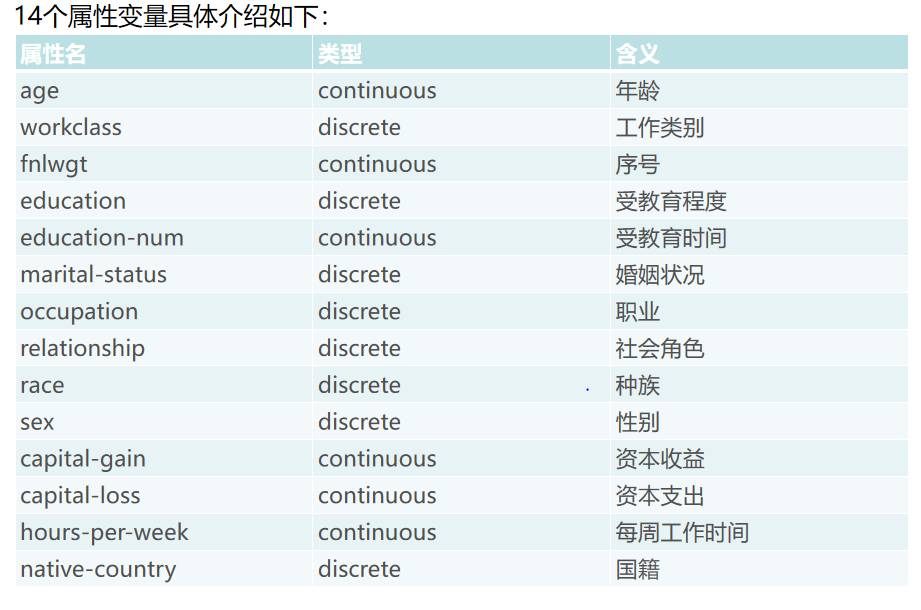
示例使用了收入分类数据集 Adult(adult.csv)。Adult 数据集是一个经典的数据挖掘项目的的数据集,该数据从美国 1994 年人口普查数据库中抽取而来,共包含 48842 条记录,年收入大于 50k$ 的占比 23.93%年收入小于 50k$ 的占比 76.07%。该数据集是一个分类数据集,用来预测年收入是否超过 50k$,属性变量包括年龄、工种、学历、职业等 14 类重要信息。
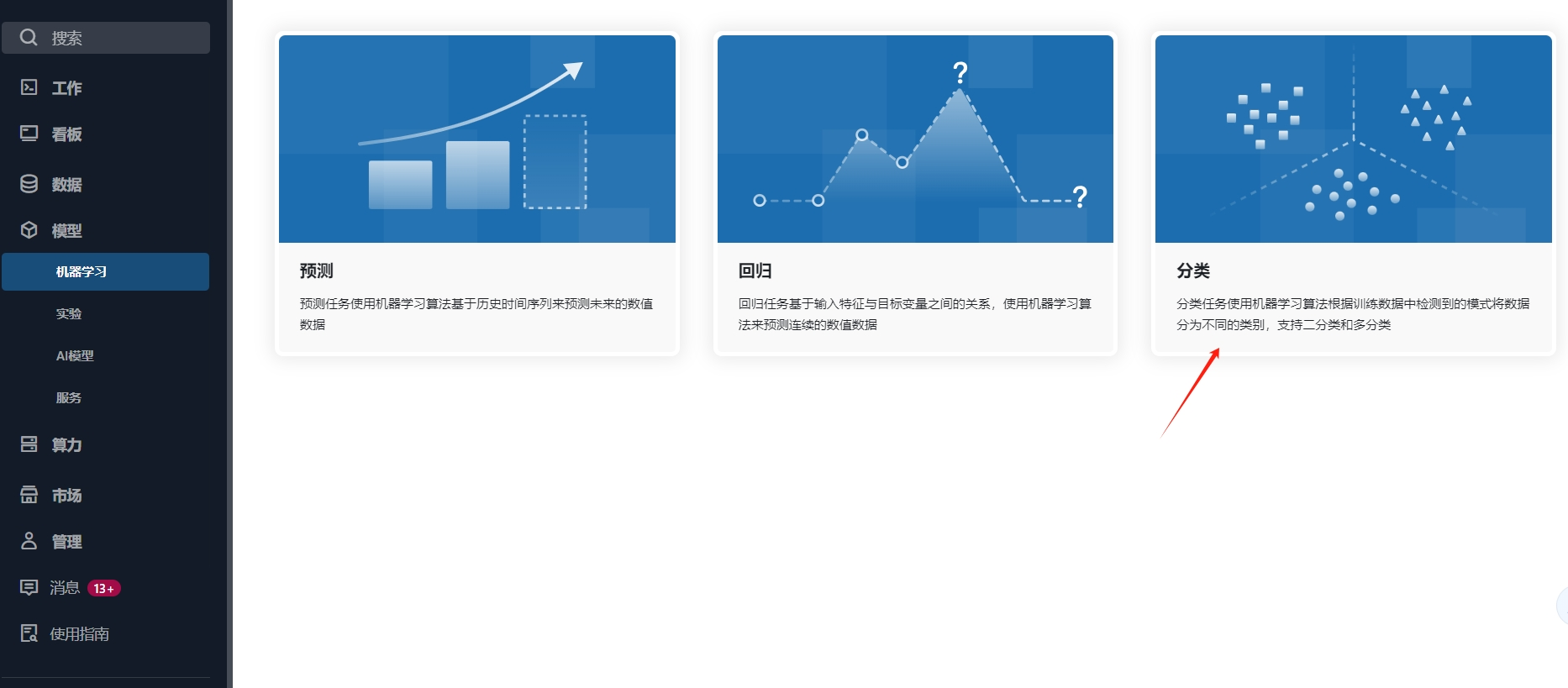
创建分类任务
- 选择分类任务
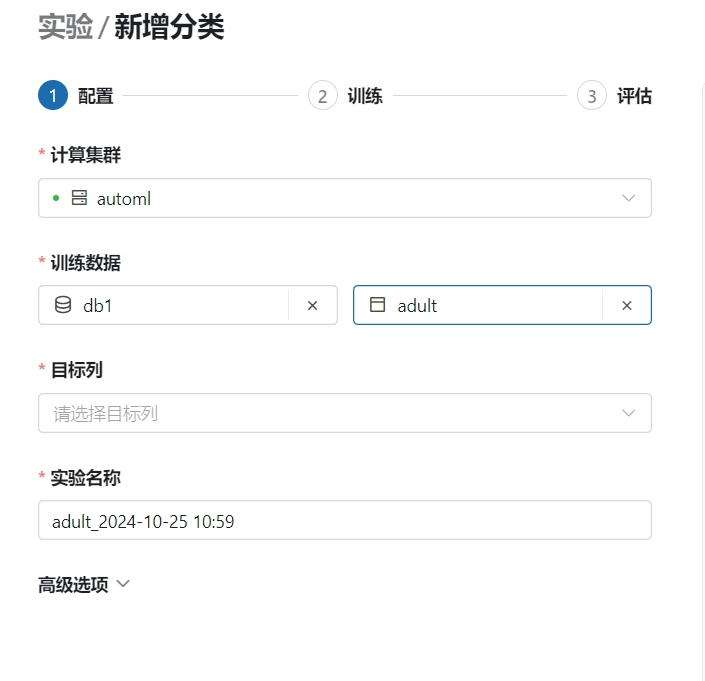
- 选择集群以及训练数据
- 选择集群以及数据库中的数据表
AutoML任务中只能选择ML类型的集群。
选择训练目标
该示例中选择income作为训练目标,除目标列之外至少需要选择一列才可以训练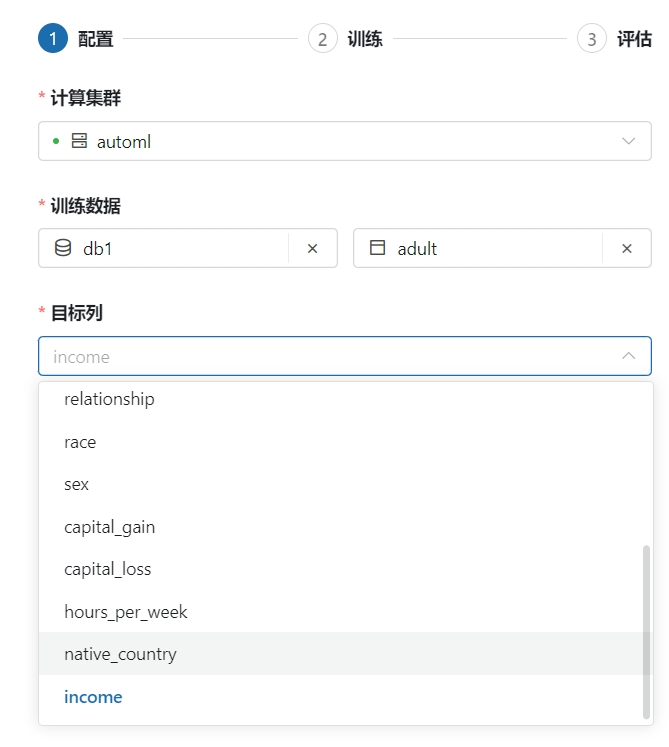
选择具体的训练列
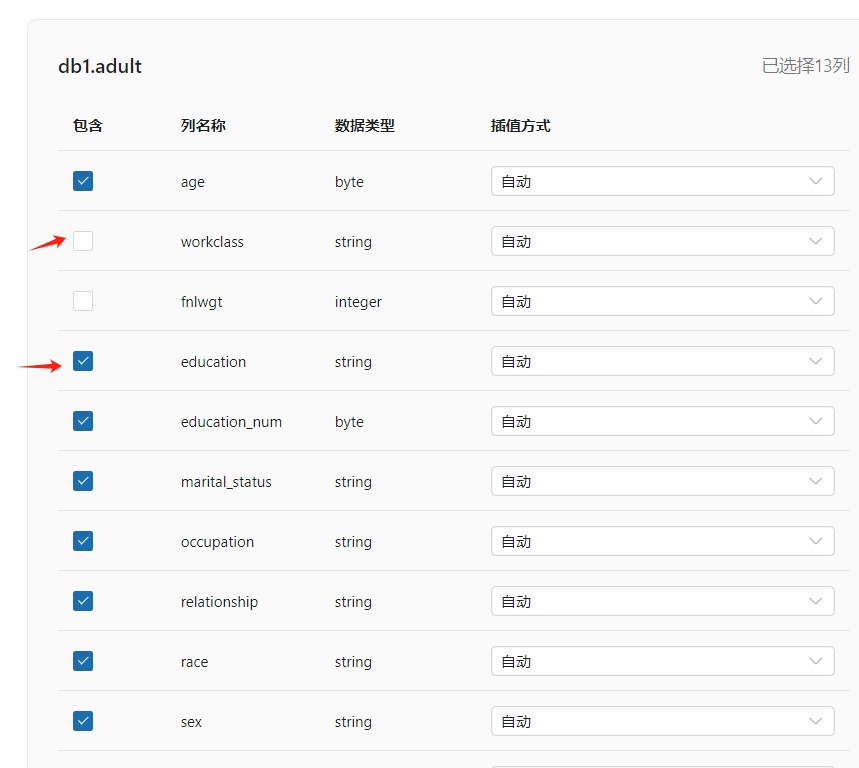
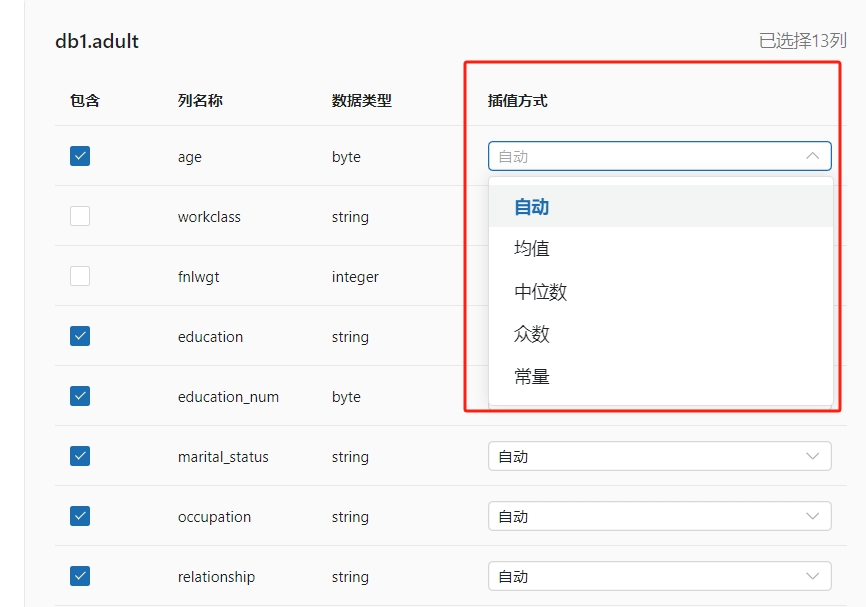
- 数据为空时的填充方式
默认为自动填充,选择常量填充时需要给定具体的填充值
- 设置训练指标、训练模型以及超时时间
实验超过设置的超时时间后会自动结束
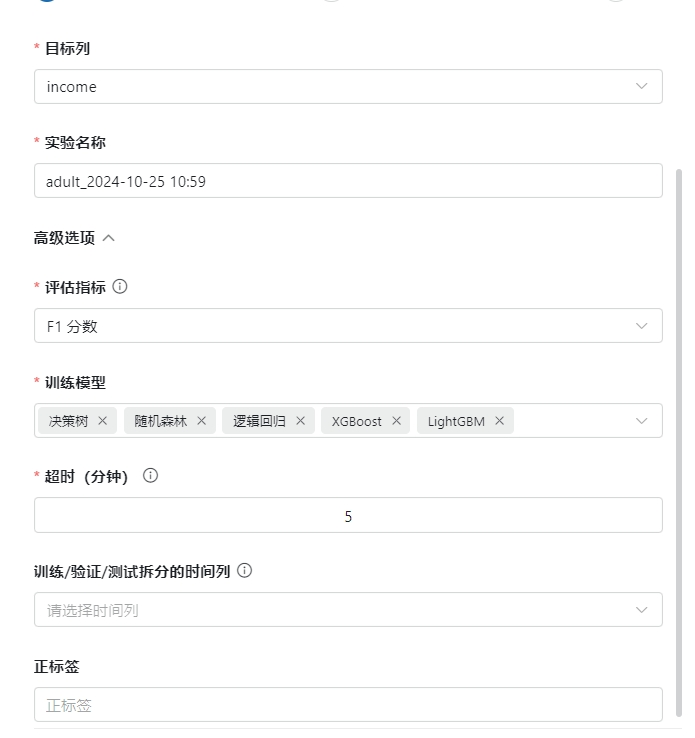
- 其他选项
时间列用于划分训练、验证以及测试数据,可以不设置
正标签用于二分类任务划分正负样本,多分类任务一般不设置正标签

- 训练
点击新增并训练开始训练
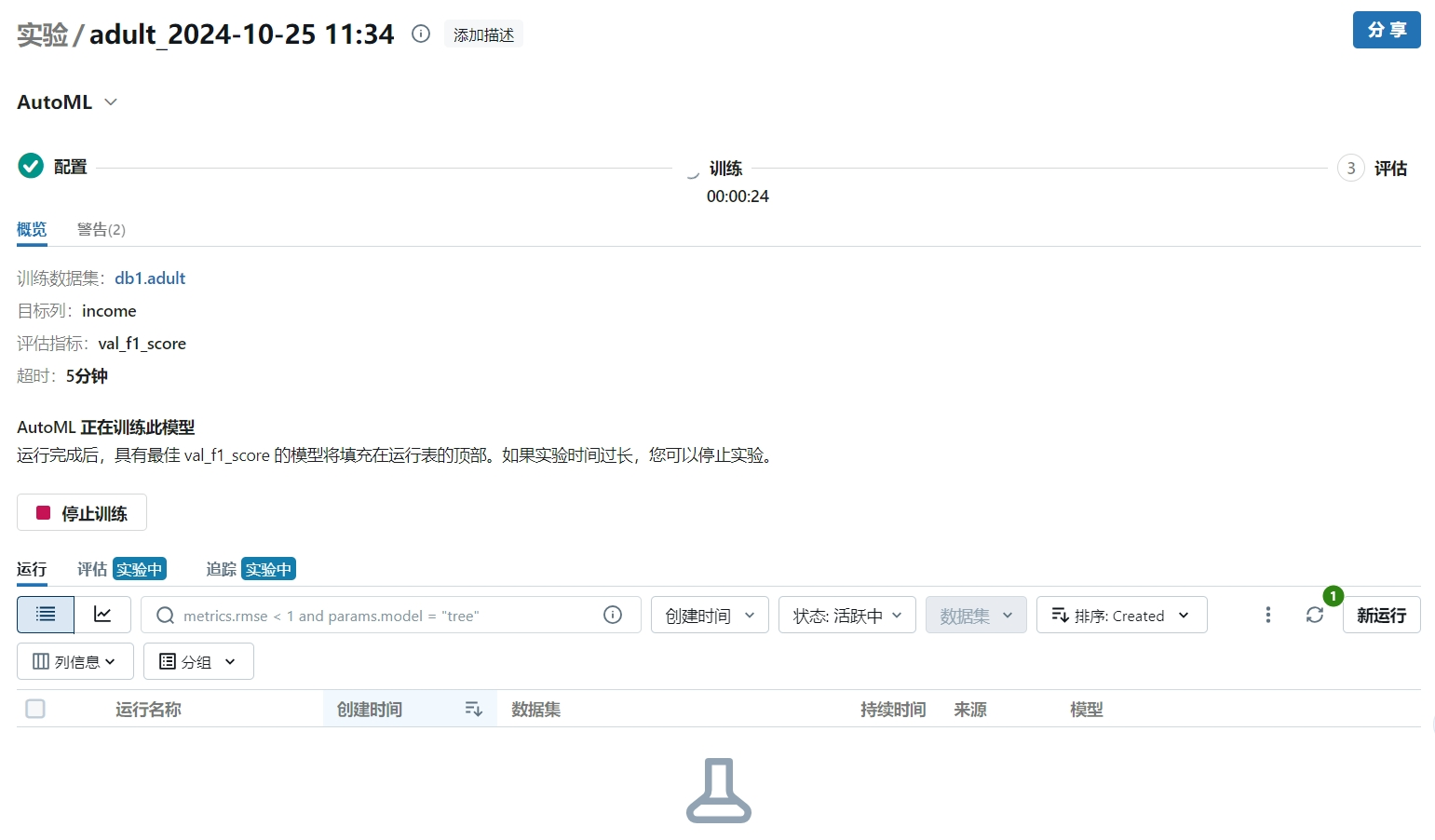
训练过程会生成可执行的 worksheet
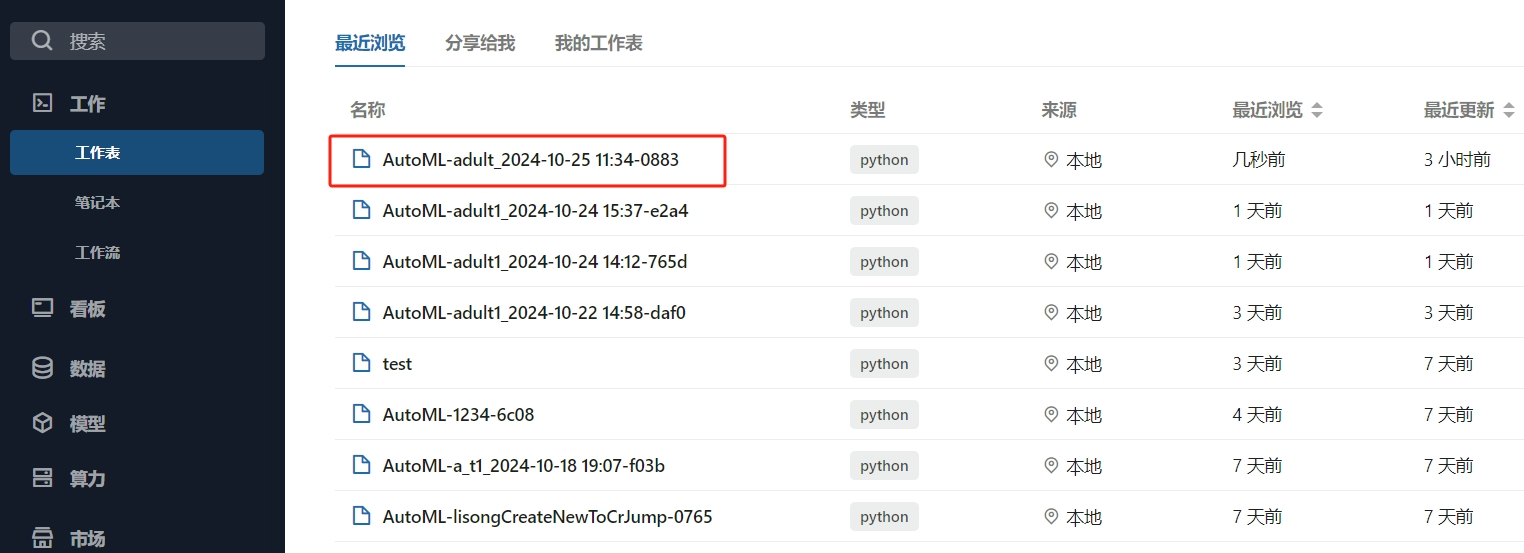
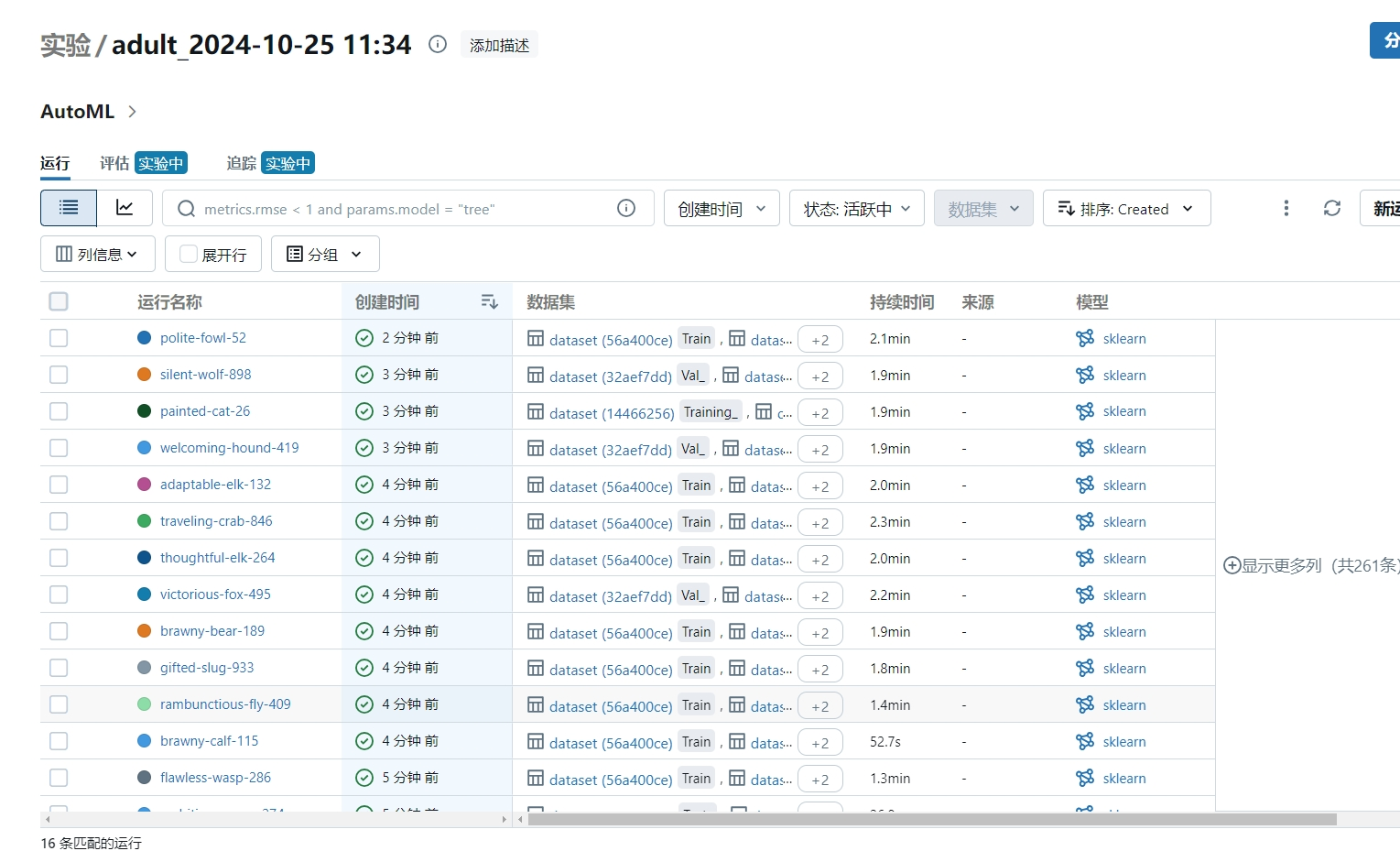
训练记录
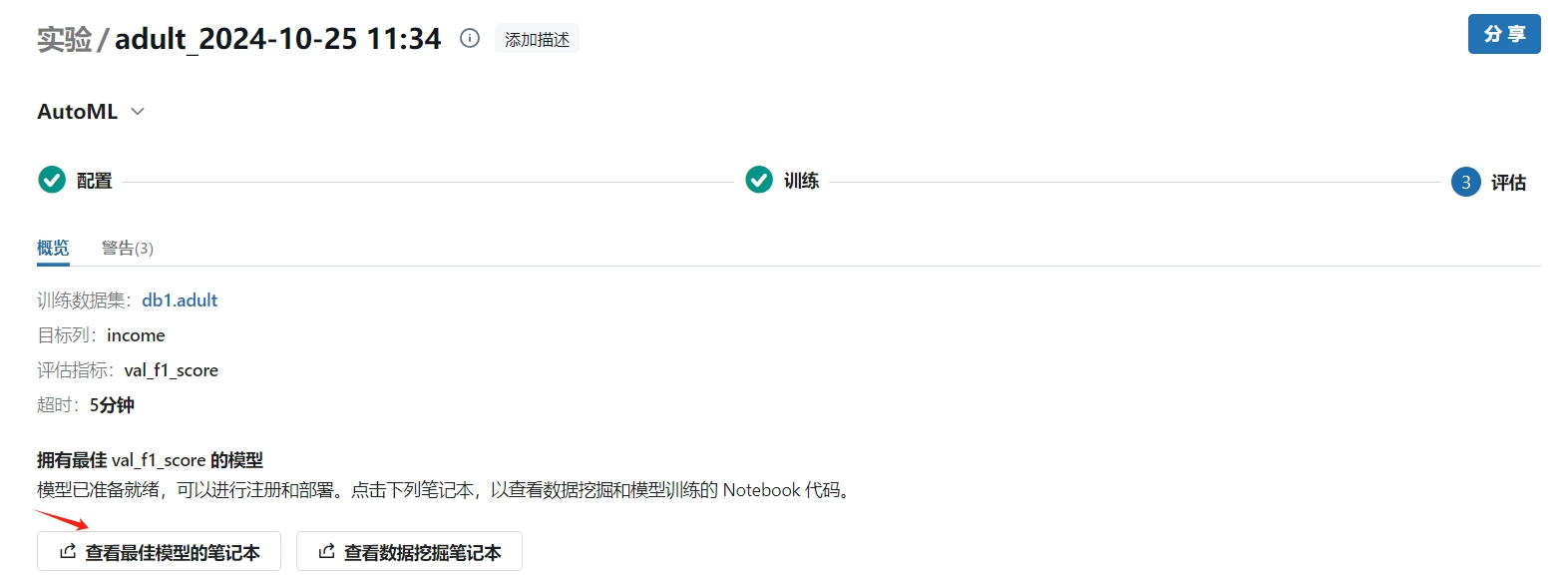
- 训练完成后会在实验中生成若干条记录
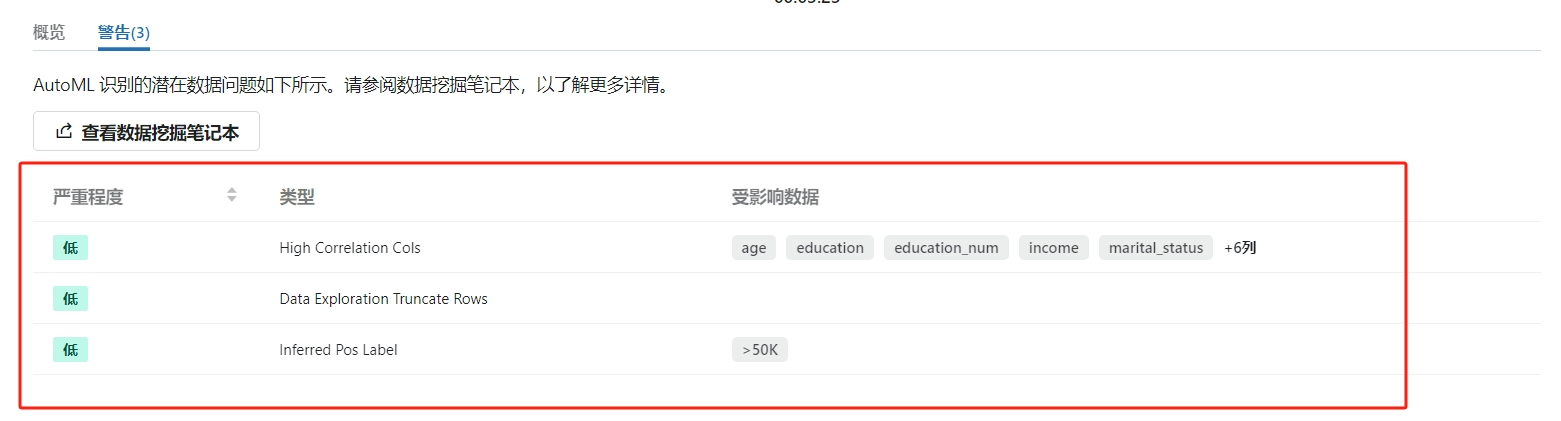
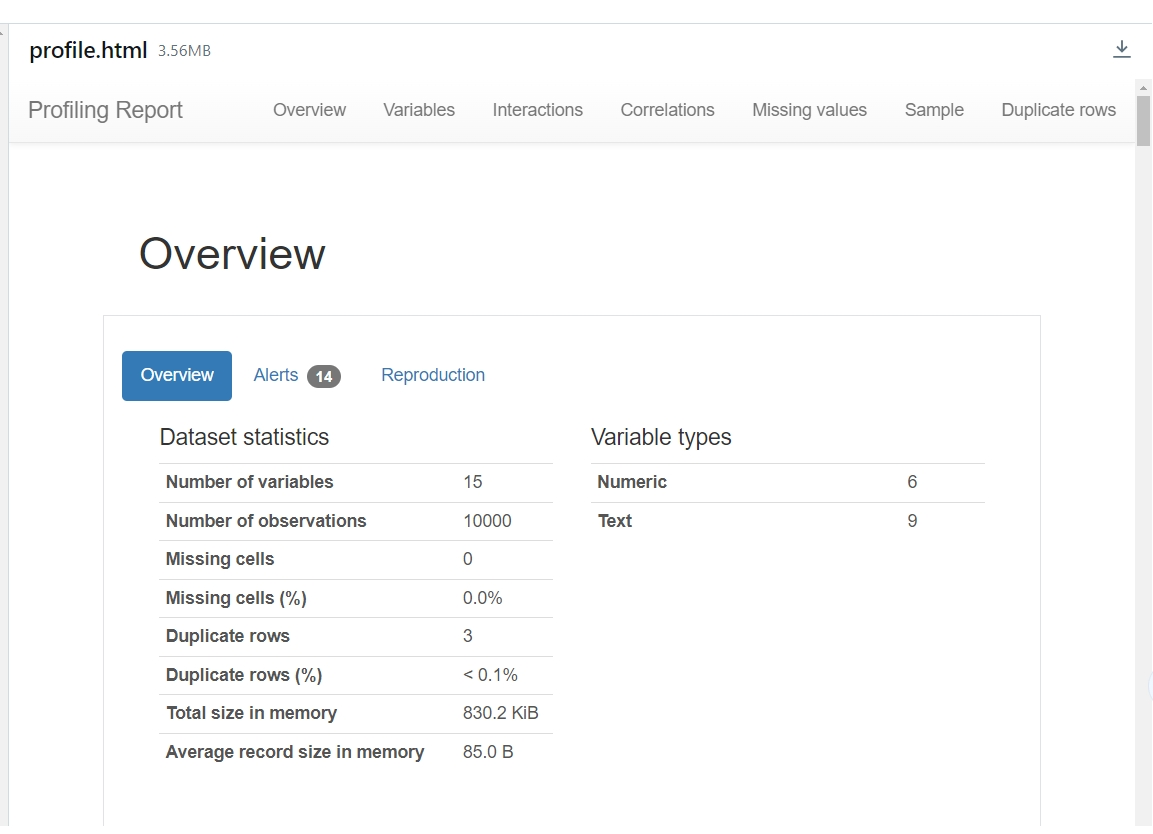
- 在数据挖掘笔记本中查看训练数据分析,包含数据统计信息等
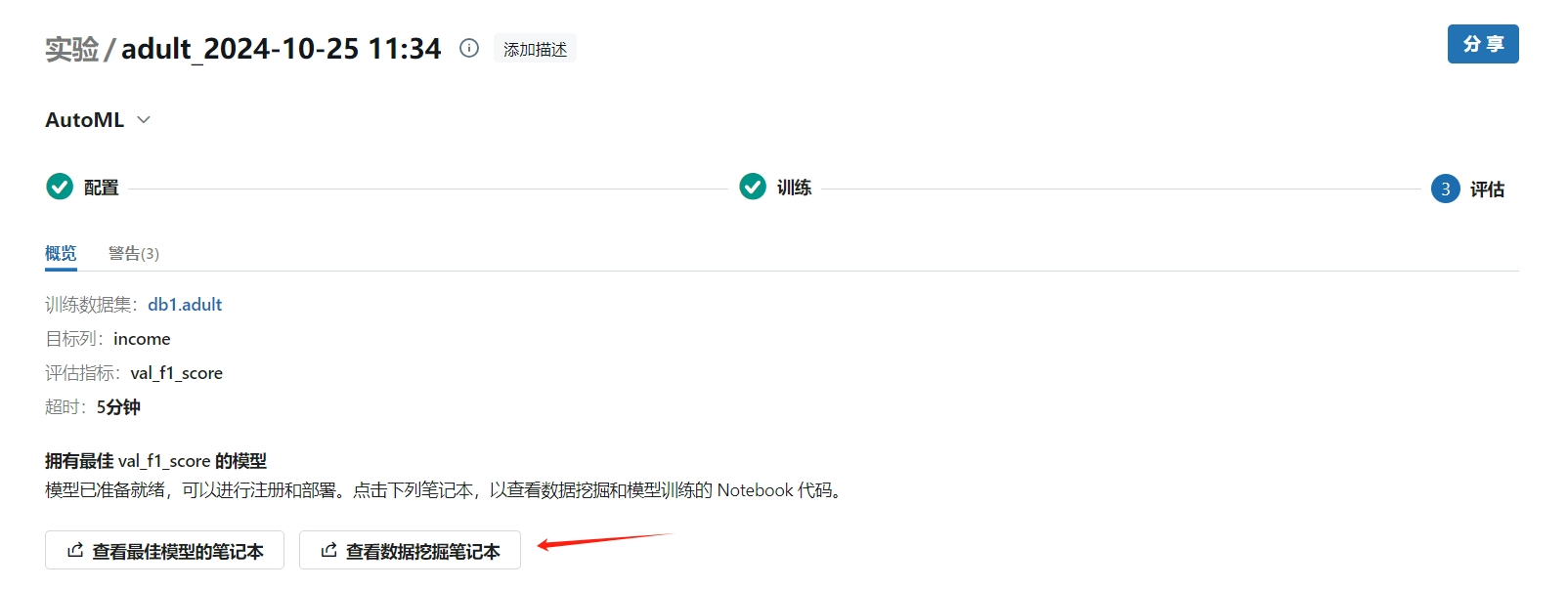
- 记录所有实验中效果最好的模型
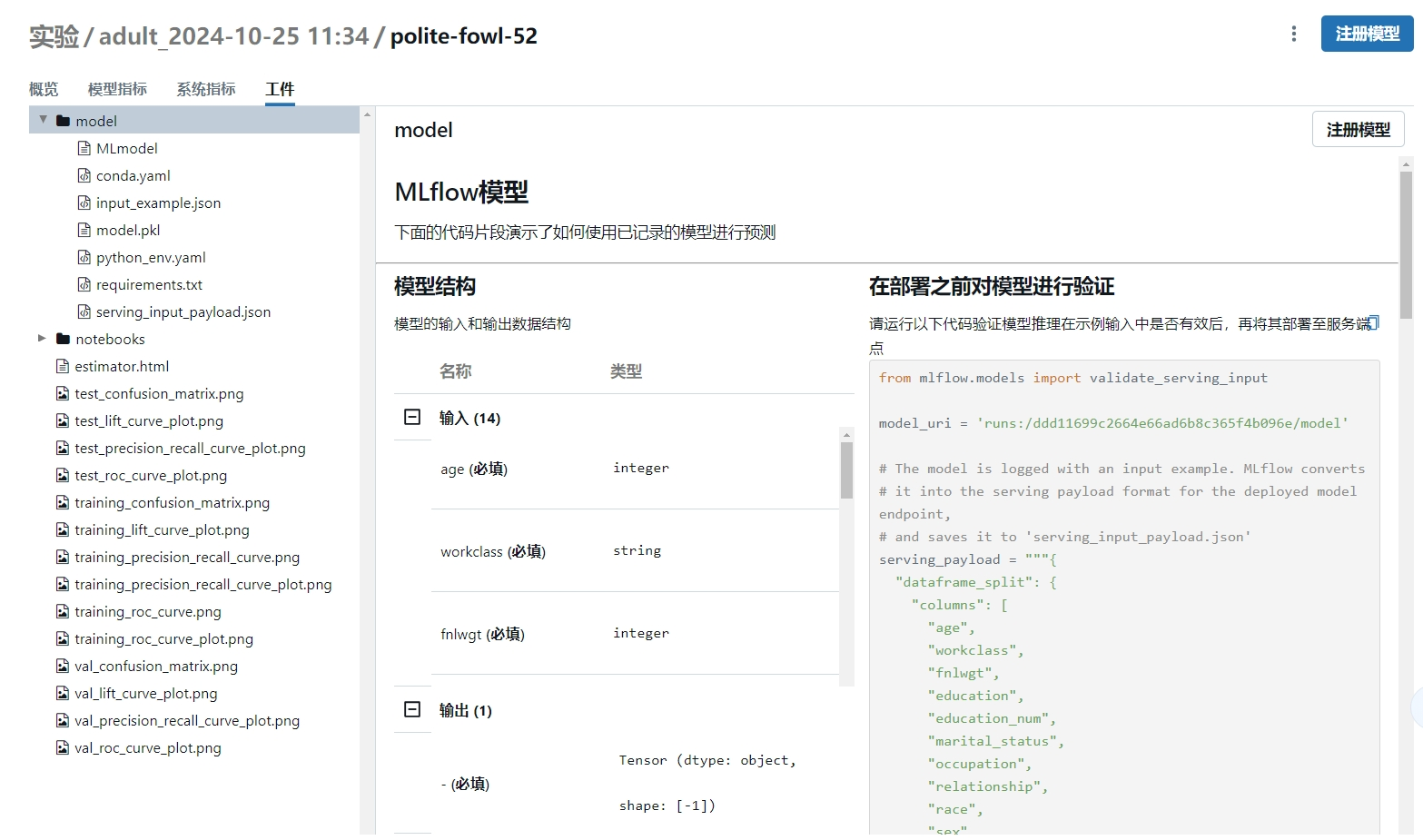
- 实验会记录训练过程中的警告