ELT数据集成
平台默认采用ELT(Extract, Load, Transform)的方式进行数据集成,即数据首先从数据源提取并加载到平台,然后在进行数据读取的时候进行必要的转换。与ETL(Extract, Transform, Load)不同, ETL的数据从数据源提取出来,经过清洗和转换后在加载到平台。
ETL的优势是可以直接将原始数据加载到平台,具有很好的可拓展性、数据源兼容性和并行处理能力。缺点是需要在后续过程进行数据清洗和质量校验。
数据提交
算场中的表是采用快照隔离(Snapshot Isolation)来实现一致性。每个表格的元数据有很多的commit构成,每个commit有唯一的单调
增加的版本号。每次提交数据会在元数据提交一个commit, commit一旦提交完成就不能被修改。
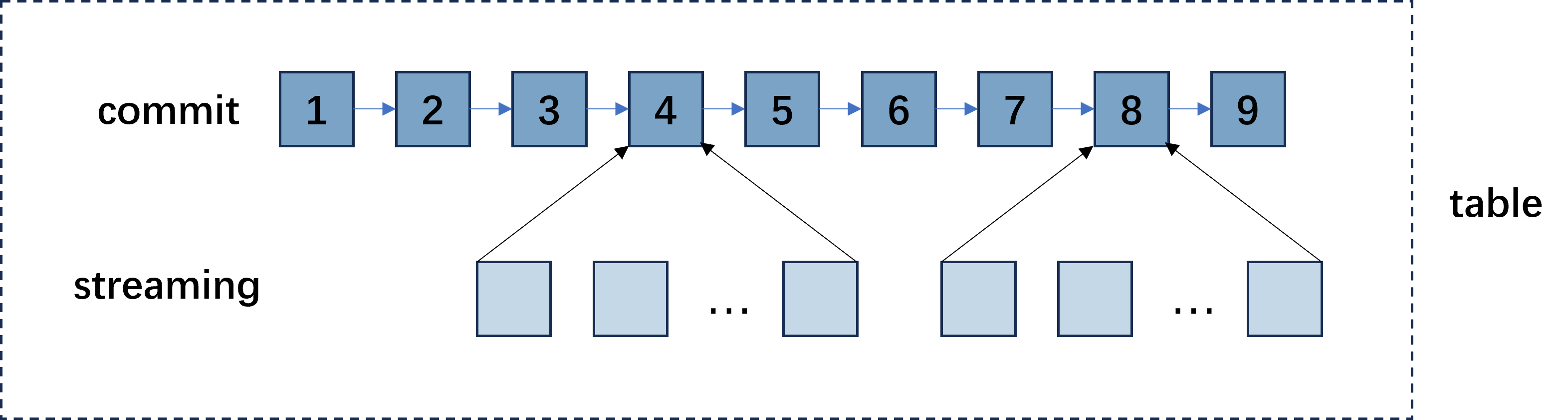
如果高频率提交大量小数据量的commit到数据表中,会导致数据在云对象存储的碎片化。尽管平台会对这些碎片数据进行合并和优化,仍会影响数据访问性能。
系统除了支持 commit 的数据提交方式,还支持 streaming 的数据提交。对于流式的每次小数据量的数据,建议以streaming的方式提交到平台。当满足一定条件,系统会自动对已经提交的streaming数据合并成一个commit添加到数据表中。通过这种方式可以有效减少数据碎片化。
无论是 commit 还是 streaming 的数据提交, 一旦提交成功,都可以无延时读取。在您使用Java SDK提交数据的时候,请根据数据源是否是流式数据的属性,选择以合适的方式提交数据。
表的结构 (Schema)
对于 ELT 的数据集成方式,每次提交的数据的结构可能是不同的。对于每一个数据表,元数据维持了两个结构:
数据结构(data schema): 记录底层实际存储的数据的结构。如果新提交的数据的结构跟表记录的数据结构不同但是兼容, 表的数据结构会根据新提交的数据结构进行演进。如果新提交的数据结构跟表记录的数据结构不兼容,会导致提交报错。
读结构(read schema): 用户指定的读取数据的结构,当读取该表数据的时候,平台会根据数据物理存储的结构和用户指定的读结构对数据进行变换,包括列类型变换、列投影等。
用户可以编辑读结构但是不能编辑数据结构,数据结构只取决于实际提交的数据。进入表格的详情页,进入列信息, 可以查看表的读结构和数据结构。其中列的名称和类型对应表的读结构,列的原始名称和原始类型对应表的数据结构。用户可以对名称和类型(读结构)进行编辑和修改。
