湖仓介绍
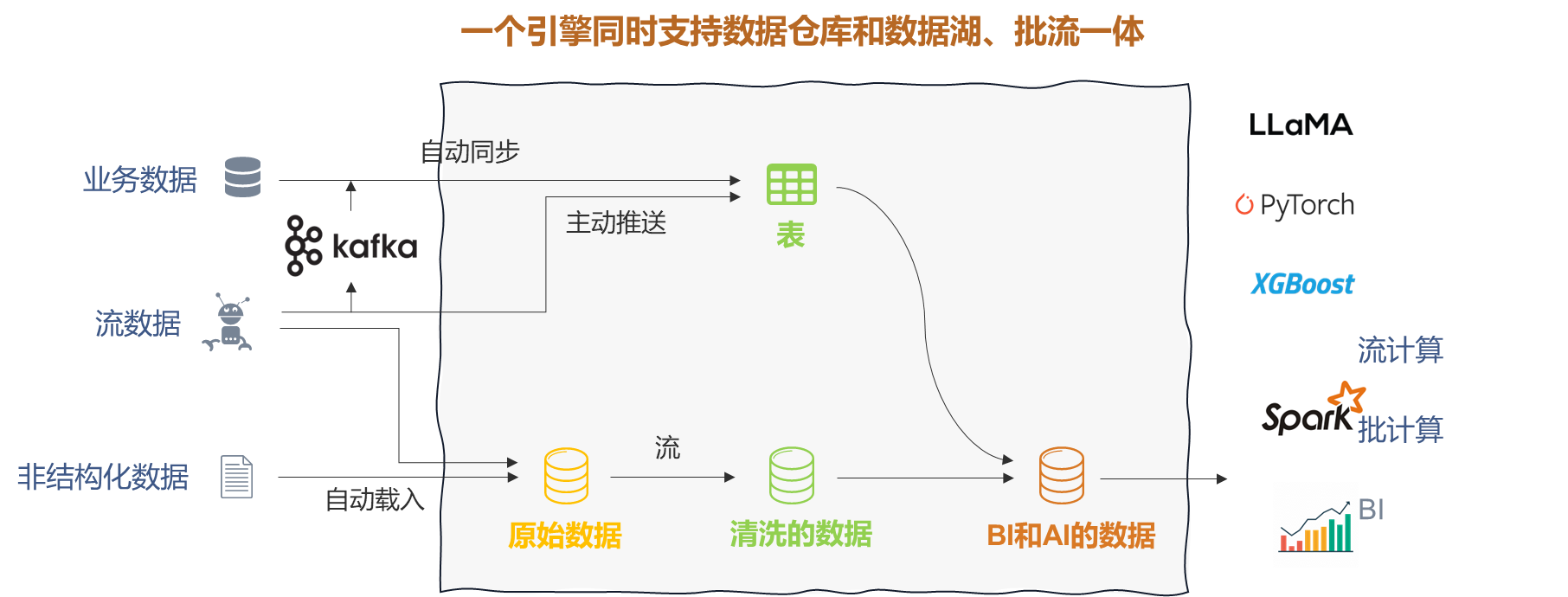
算场湖仓的系统工作机制
算场湖仓是在Apache Spark基础之上构建的。Apache Spark是一个可大规模拓展的分布式计算引擎,可以支持灵活的分布式处理。关于Apache Spark,请参阅Apache Spark。
算场湖仓构建了几项关键技术:
- 针对分布式优化的列式存储。
- 针对云对象存储的存储缓存层。
- 支持ACID事务以及查询和处理优化。
- 针对数据和AI的统一数据管理和治理。
算场湖仓的功能
算场湖仓使用统一的引擎覆盖了数据湖和数据仓库的你能力,主要功能包括:
- 数据加载和集成: 支持使用一套系统统一组织所有结构化和非结构化数据,为组织建立统一数据来源并实现数据协作。
- 批流一体:支持大规模批数据的处理和计算,同时支持流数据的实时处理和分析。
- 数据转换: 通过弹性算力和基于Apache Spark的编程处理能力实现数据灵活的、可伸缩的处理。
- 数据结构演化: 可以随时调整数据结构以适应不断变化的数据源和业务的需求。
- 数据分析和报表: 可以支持复杂的分析查询、可视化以及看板监控,借助于大模型支持语言交互的自动化分析。
- 机器学习和AI: 应用机器学习和AI到数据,支持高级的分析技术。
- 数据版本控制: 维护数据集的版本历史记录,支持数据的恢复和追溯。
- 数据共享: 支持组织内和跨组织的数据和报告共享,在安全可控下实现数据流通和协同。
数据湖仓、数据湖和数据仓库
数据湖仓将数据湖和数据仓库结合起来。数据仓库可以优化结构化数据的查询,驱动商业智能(BI)决策。数据仓库通常依赖于特定的结构化数据结构,限制了复杂数据处理和机器学习的能力。数据湖可以高效且廉价的存储和处理任何格式的数据,并用于数据科学和机器学习,但是这种自由度导致它并适合需要验证的查询和 BI 任务。
数据湖仓结合优化的元数据存储和云对象存储,支持复杂的结构化数据查询以及对大规模非结构化数据的处理和分析能力,允许数据科学家和机器学习工程师从统一的数据上进行数据驱动的商务智能和多种多样的人工智能模型的构建。
并发事务管理
算场使用乐观并发控制来管理并发事务。在读取表时,提供表的快照隔离(Snapshot Isolation)。在写入时提供写可序列化隔离 (WriteSerializable)。它仅确保写入操作(而非读取)可序列化,对很多常见操作,它使数据一致性和可用性之间达到良好的平衡。
在乐观并发控制机制下,数据写入操作可以分成3个过程:
读快照: 从元数据存储中读取表的快照,包括表的最新可用版本以及相应的云对象存储文件。如果仅追加(append)的写入操作不需要在写入之前读取表的状态。
写入数据文件: 基于表的快照得到本次操作需要写入的数据,并保存到云对象存储中。
验证和提交: 检查本地提交的操作是否与读表快照依赖可能并发提交的其他操作想冲突。
- 如果没有发生冲突,则本此提交的操作成功提交为表的新版本,写操作成功。
- 如果发生冲突, 则写操作失败,并删除本地操作所创建的云对象存储文件。
Apache Spark
Apache Spark 是一个广泛使用的分布式计算开源项目。算场湖仓的执行引擎构建在 Apache Spark 之上, 用户可以使用标准SQL语法来创建和查询数据库对象, 系统对数据存储、查询任务和机器学习进行了优化。
借助于 Apache Spark 的计算能力, 用户可以对数据进行灵活的计算和处理。